
In the age of social media, companies are conscious about the reviews that are posted online. Any act of dissatisfaction can be meted out by way of tart sentiments on these platforms. And so enterprises strive hard to give 100% positive experience, by doing all that they can to address customer grievances and queries. But like they say, there are slips between the cup and the lip – not all grievances can be handled amicably.
Let’s take the specific case of call centers here. Their Service Level Agreement mentions terms like number of calls answered at a certain time of the day, percentage of calls answered within a specific waiting time, etc. Ensuring customer satisfaction and retention requires a far deeper, more holistic view of interaction between customer care representative (agent) and caller. There are other KPIs such as what causes a customer to be dissatisfied and number of escalations. But these seldom find a place in the SLA.
In this article, we will talk about identifying drivers of (dis)satisfaction and come up with ways to improve it. In the course, we will touch up on the solution design that can scale and institutionalize real-time decision making.
Introduction
We’ve all done it, dialing the call center for any issue encountered. We are surely an expressive bunch when it comes down to rattling our emotions and spitting out our dissatisfaction. And if that is not enough, we threaten to let our dissatisfaction be known to the rest of the world – through social media, not to mention #CustomerExperience.
While standard surveys exist to capture the sentiments of customers, the percentage of people filling these surveys is very low. This compounds the problem of effectively addressing customer needs.
Automating the task of predicting customer satisfaction requires a balanced mixture of text mining, audio mining, and machine learning. The resulting solution needs to:
- Scale and be deployable
- Identify the drivers of dissatisfaction
- Generate actionable insights and generalize well to the population
Modeling Pipeline
Modeling pipeline includes all the components (data ingestors, model builder, model scorer) that are involved in model building and prediction. It is mandatory for the modeling pipeline to seamlessly integrate all the components for it to be scalable and deployable – production worthy. These components vary depending on the problem, available architecture, tools used, scale of the solution and turnaround time. The following pipeline was built in Google cloud to solve the problem of dissatisfaction in call centers.
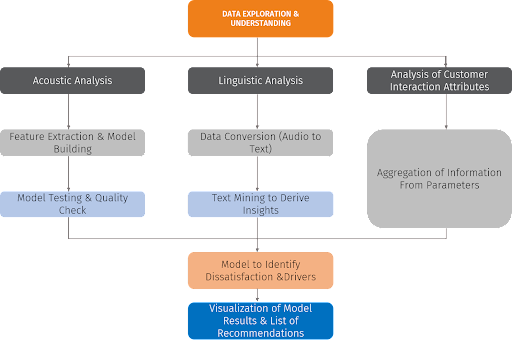
Modeling (actual work – driver identification)
In the above problem, the satisfaction survey showed good internal consistency. Calls, emails and chats had sufficient discriminatory power to model customer satisfaction. Exploration of the data showed that the patterns were non-linear. However, like other psychometric models, the satisfaction model was plagued by three major issues which threatened its external consistency: shortage of data, variance and instability. These problems were addressed in the following manner:
First, the issue of data shortage was solved using resampling (bootstrapping). Second, the challenge of model instability was resolved using k-fold cross validation for tuning hyperparameters of different models. This was followed by model averaging. Finally, the issue of model variance was solved using stack ensemble approach on bootstrap samples. Several classification algorithms were used to build the first layer of the stack. Logistic regression was used to predict the outcome by combining the results from the first layer. The accuracy thus obtained was superior to that of any individual model in the first layer of the stack.
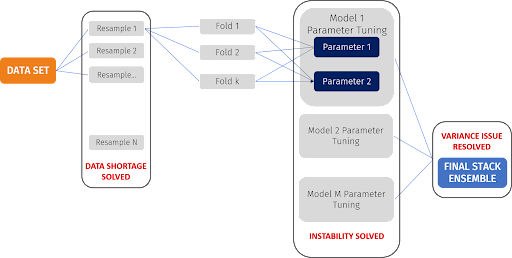
Driver Analysis
Only two types of classification models are directly interpretable: logistic regression and decision tree. Interpretation of other Machine Learning techniques such as regularized regression and regression splines require knowledge of calculus, geometry and optimization. Machine Learning models such as support vector machines and neural networks are considered black box techniques because of the high dimensionality, which is difficult for the human brain to comprehend.
Standard measures of variable importance exist for commonly used black box techniques such as SVM and neural networks. Simple weighted average method is used to calculate the importance of variables in the stack ensemble, with the weights being determined by the logistic layer. However, it is important to note that the final importance is not a measure of linear dependence of satisfaction on the independent variables. The importance metrics need to be combined with business intuition and actionability to provide recommendations for improving customer satisfaction.
Consumption
A call center manager would like to track customer satisfaction level along with several KPIs that are critical to operation. Information related to utilization of customer care representatives is provided to the manager in real-time. Model prediction is run in semi-real-time to reduce the required computational power. The manager is provided with options to deep dive into historical data based on variables that are drivers of dissatisfaction. For example, calls can be redirected to customer care representatives by existing ERP systems based on their history and subject matter expertise. This reduces the number of escalations and enables near real-time actionability without significantly affecting other KPIs.
The problem of customer dissatisfaction in call centers can be solved using audio mining, text mining and machine learning. Intelligent systems greatly reduce the stress on customer care representatives by automating the majority of the processes. These cloud-based systems can be seamlessly integrated with existing ERP systems to provide highly actionable insights about dissatisfaction without significantly affecting other critical KPIs that are related to call center operations.
Topic Tags





