
 LinkedIn
LinkedIn
In the previous blogs, we have explained Unity Catalog, how to set it up, and the benefits of the data governance that Unity Catalog offers.
Once an organization is ready to move to Unity Catalog, the next step is to move existing Databricks workspaces to Unity Catalog. While there is not much change to the logic of the data pipelines, Tredence has learned that a few things must be considered when moving to the Unity Catalog. Let’s take a deeper look at them. Enterprises adopting data engineering services for Databricks can significantly simplify migration while ensuring scalability and governance.
Mountpoint to be changed to Unity Catalog External Table
One of the common ways to read and write data to the data lake is using mount points. Mounting is a process in Databricks that links Databricks workspace and storage account. Now that the mount point is not supported as part of the Unity Catalog, all mount points need to be changed to external locations, which can be governed through access control. This is a significant change as mount points are used to create a spark dataframe from the data lake and external tables pointing to datalake.
Below is how mount points are used to read data from datalake:
In Unity Catalog, the mount point must be replaced with an external location. External location is created using storage credentials in the data explorer Tab in DBSQL.
The external location can be governed for read and write access to the datalake.
Once this is created, the mount point needs to be replaced by the external location as below.

Managed and External Tables on Unity Catalog
Let’s understand the difference between managed and external Delta Tables in Databricks. External tables in Databricks are just metadata of the table structure in the Hive metastore, which points to data in the data lake. Even if the table is dropped, the data in the data lake remains unaffected as dropping the table drops the metadata in Hive metastore and not the data. Databricks only manages the metadata and not the data in the data lake.
Managed tables, on the other hand, are operated by Databricks. The metadata (structure of the table) and the data are collected by Databricks. The data and metadata are tightly coupled, meaning if the table is dropped, the metadata and data are deleted.
This is an important consideration as moving existing managed tables to Unity Catalog needs data to be moved from managed tables to data lake storage accounts or managed tables in Unity Catalog.
As a best practice of Unity Catalog, it is always preferred to use managed tables as Databricks has a number of inbuilt optimizations like optimizing file sizes.
For new applications it is suggested to use Unity Catalog managed tables but for existing applications, it is suggested to use external tables in Unity Catalog as data migration to Unity Catalog managed tables can take up significant resources and cost.
Upgrade steps
The following steps will be performed by the Metastore Administrator.
Create a Unity Catalog-enabled cluster (DBR 11.1 or later, “Single-User” Security Mode).
Create CREDENTIAL via the Data Explorer UI in DBSQL documentation.
Create EXTERNAL LOCATION, either via the Data Explorer UI in DBSQL or with the below command documentation.
Grant Permission to CREATE TABLES, READ FILES, and WRITE FILES to the user/principal who will run the Databricks job. It is recommended that a principal will run the job rather than a user.
Create a Catalog and Database for the target table.
Grant access to the user performing the upgrade as well as to the user/principal running the streaming job.
The following steps can be performed by a developer. The developer has to be granted CREATE TABLES, READ FILES, and WRITE FILES rights on the external location. The users must be given access to a UC schema or permission to create one.
To move the existing managed table to the external table, perform the following steps:
Copy data from managed tables to datalake by creating a dataframe and writing the output of the datalake location using a mount point.
Create an external table in Unity Catalog metastore using External Location to point to the data in datalake.
To move the existing managed table to the Unity Catalog managed table, perform the following steps:
Deep clone the old target table to a newly created table in the Unity Catalog.
Once the table is registered in the Unity Catalog, all upstream and downstream linkages must be modified to use the Unity Catalog tables.
Remove all Hive Metastore references.
Once the tables are moved to the Unity Catalog, Databricks code must be modified to point to the Unity Catalog table.
Below is a sample code on how we can retrofit code to point to the Unity Catalog table:
Pass environment parameters in a notebook.
A significant change that Unity Catalog brings is that tables in Unity Catalog, irrespective of environment, are stored in the same Metastore (assuming all workspaces are in the same region).
The Unity Catalog will have DEV, QA, and PROD environments catalogs in the same Unity Catalog metastore.
For example, if you have a catalog for the Procurement domain, you will need to structure the catalog in the following manner. This is just a representation, and the structure of the catalog and schemas can vary.
If you notice, the catalogs are prefixed with the environment to differentiate the objects of DEV, QA and PROD. Hence, every notebook in the application must be passed with environment values (dev, QA, prod) to append the environment name with the catalog name to reference the table in the environment.
So, the DEV workspace will need to be passed with a parameter of “dev,” the QA workspace will need to be passed with “qa,” and the PROD workspace to be passed with “prod” to enable the workspace notebooks to read and write from the environment catalog and objects.
Below is an example of how the “environment” parameter is used in a notebook
Pass the data lake name as a parameter in the notebook.
In most organizations, the data lakes across environments are separate. For example, for development, there will be a separate dev datalake, the QA environment will have a QA datalake, and the PROD environment will have a prod datalake.
When a notebook code reads data from a data lake, now that we need to use an external location, which is the only way supported by Unity Catalog to read data in a data lake, it is also necessary to pass the data lake name to the notebooks that read data from the data lake. The external locations are created with the data lake name as part of the external location.
The format of the external location is as below (abfss://container/datalake.dfs.core.windows.net/folder)
Example:
The data in the datalake will need to be read using this external location.
df = spark.read.csv (“abfss://tredence-test@ zenithswestuse2 .dfs.core.windows.net/filename.csv”)
The above code needs to be parameterized using widgets (like in the case of the environment) to pass the datalake name to modify the code to enable moving the code across the environment seamlessly.
df = spark.read.csv (f“abfss://tredence-test@ {datalake_name} .dfs.core.windows.net/filename.csv”)
Orchestration changes to pass parameters to the notebook.
As notebooks need to be parameters, the orchestration solution must also be changed to enable passing parameters to the notebook. So, assume the orchestration is through Databricks workflows, Azure Data Factory, or Airflow. There are changes in the code where notebooks are called to pass the environment parameter as well as the datalake parameter (in cases where notebooks read data from datalake).
Catalog, Schema, Object level access in Unity Catalog
As objects are created in the Unity Catalog, it is needed to grant appropriate access to the new object. By default, the user or principal that makes the object becomes the owner of the object. It is required to build code as part of ETL to change ownership of objects to the right principal/group, which can be done through grant queries as part of notebook code. It is also possible to create a code externally to data pipeline notebooks that runs on a schedule to grant appropriate ownership of objects in the catalog.
|
Unlock AI-Ready Data Governance with Unity Catalog
Migrate faster and enable enterprise-grade governance for GenAI and analytics. Get Started with Tredence |
Downstream changes to the application
Applications that read data from Databricks using Databricks SQL Warehouse example, Power BI, web applications must use the tables in Unity Catalog using the catalog.schema.tablename instead of schema.tablename.
Apart from these, there are also changes concerning the cluster types and commands that will refer to the dbfs location, which need to be retrofitted for Unity Catalog (see the previous blog on Unity Catalog Cluster types).
So, we understand that there is no logical change. Still, there are unavoidable code changes in the notebooks that need to be done without impacting data provisioning to downstream applications. But how do we upgrade the Databricks workspace and retrofit code for Unity Catalog? Organizations often leverage enterprise data platform modernization frameworks to streamline such migration efforts and minimize risks
Below are two options to do so.
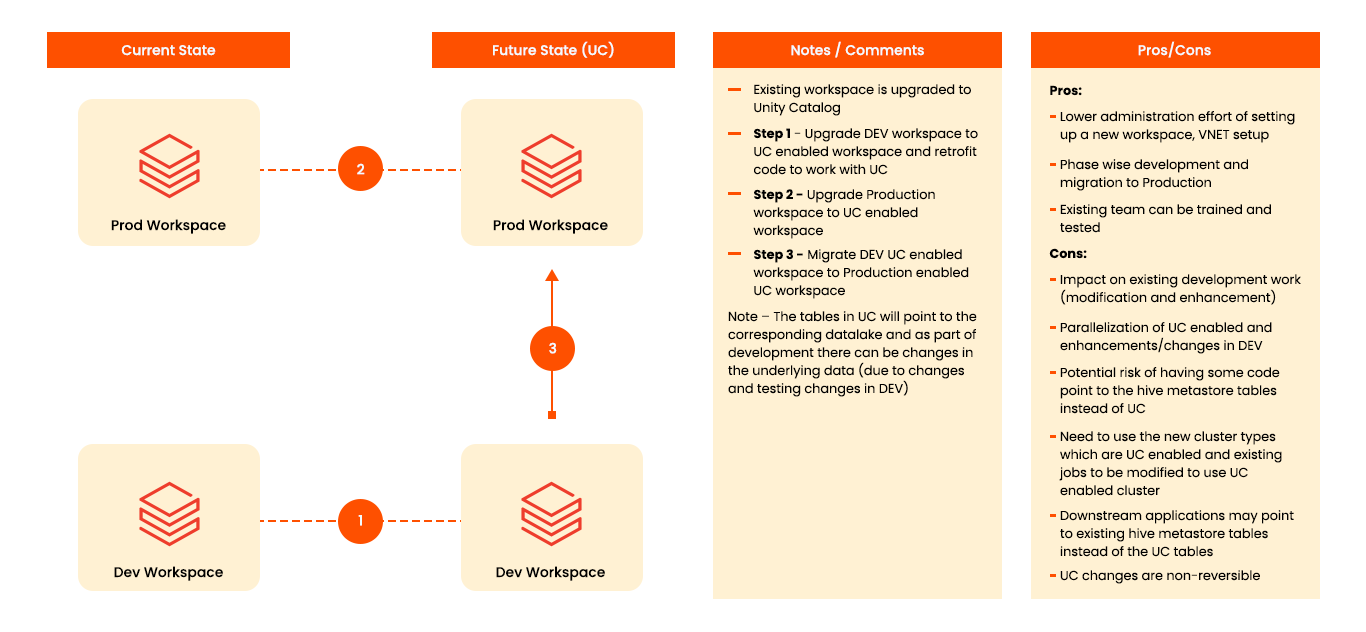
Option 1 – In-place Upgrade
In this option, the DEV and PROD workspaces are upgraded to Unity Catalog, code changes are made in DEV, then moved to the PROD Unity Catalog enabled workspace.
Below is a representation of how the in place upgrade looks:
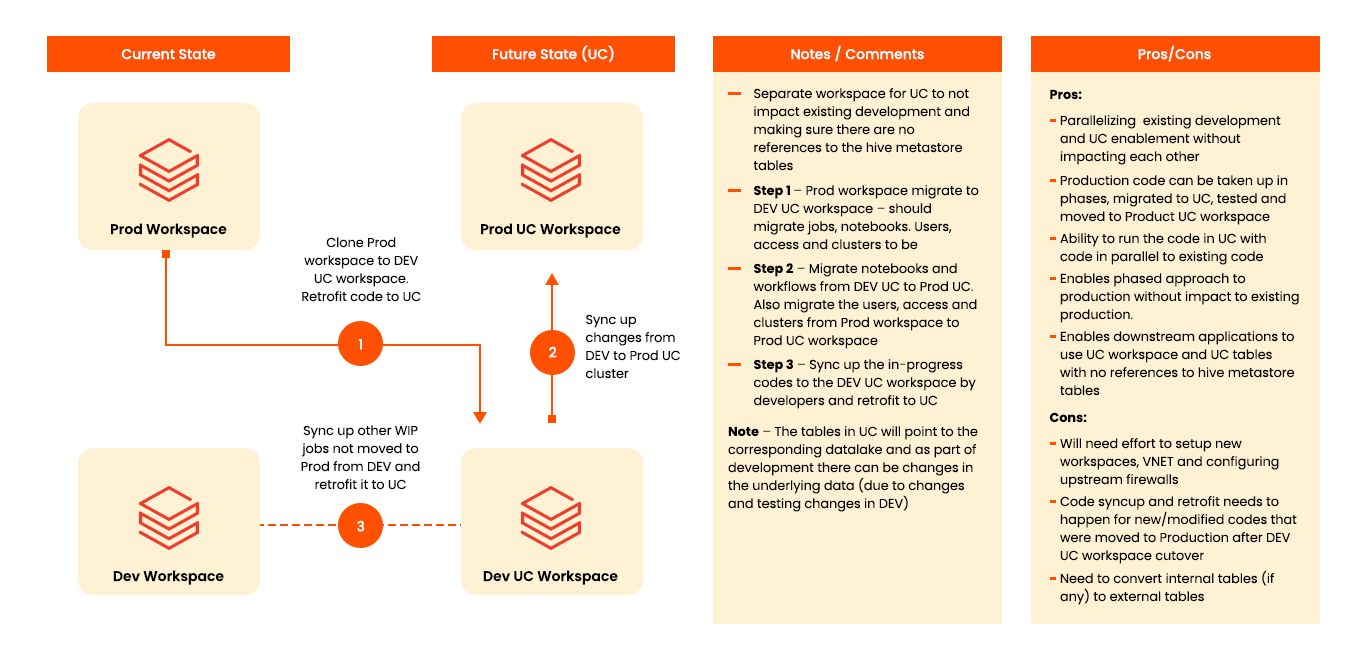
Option 2 – Build Separate Workspaces for Unity Catalog Enablement
In this option separate DEV and PROD Unity Enables workspaces are created. Code from existing Production is migrated to Unity Catalog DEV workspace, code is retrofitted for Unity Catalog, and then migrated to new PROD Unity Catalog workspace. Additional code in the DEV environment is then synced up in the new DEV Unity Catalog workspace to continue development on the DEV UC cluster.
Below is a representation of how using separate workspaces works:
Below is Comparing Options 1 and 2
|
Criteria |
Option1 (In Place) |
Option 2 (New UC Workspace) |
|
Parallelize development with existing changes |
 |
|
|
Lower Risk of Migrating Applications |
 |
|
|
Phase wise migration |
 |
|
|
Guardrail to using UC tables for data loading and downstream with no reference to hive metastore |
 |
|
|
Lower complexity of setting up the environment and upstream firewall changes |
 |
Based on this, Option 2, i.e., creating a new Unity Catalog-enabled workspace and migrating, is recommended.
This option enabled migrating to Unity Catalog phase-wise in a controlled manner without impacting business continuity. Applications can be properly tested on Unity Catalog before migrating to the PROD Unity Catalog environment, and downstream can be planned and moved to the new workspace.
Please note that there is no data movement in Option 2, i.e., creating new Unity Catalog workspaces (unless there are managed tables in the application and migration, as explained above). We can continue to use the same data lake and point the Unity Catalog tables to the data lake through the Unity Catalog external location. The only watch-out is that since the old workspaces and Unity Catalog workspaces have the same datalake, any data modifications for development or testing in one environment will reflect in the other.
Tredence has come up with a hybrid approach that is the best of the two options where the code can be migrated to a test workspace (outside of current application workspaces, tested there and then merged into the existing environment. This enabled testing the application outside of current application workspaces but still using the existing workspaces where tested code can be merged into the existing workspaces
Tredence has been able to create an accelerator working with the Databricks Field Engineering team to automate the migration of existing workspaces to the Unity Catalog using the above hybrid approach.
Summary/Conclusion:
To summarize, code changes need to be considered while moving to the Unity Catalog. Tredence’s recommended option is to provision new Unity Catalog-enabled workspaces, migrate the code, migrate the table structures, and retrofit the code in the new workspace to enable business continuity and plan the cutover to Unity Catalog.
Databricks Lakehouse Platform is a powerful data platform allowing for real-time access to structured, unstructured, and new data sources that can be used for advanced analytic applications across enterprise applications. Tredence has developed extensive expertise in deploying Unity Catalog through the many migrations it has delivered. Once Unity Catalog architecture is embedded in a firm’s digital operating model, Tredence’s vertically-centric purpose-built use cases (Brickbuilders) can be deployed to provide real-time insight or deliver predictive actions ranging from revenue growth management, customer experience personalization, supply chain optimization, or event manufacturing process optimization.
Power your AI, analytics, and enterprise applications with Unity Catalog and Tredence’s Lakehouse expertise.
FAQs
1. What is Unity Catalog in Databricks?
Unity Catalog is a unified data governance solution in Databricks that enables centralized access control, auditing, and management of data and AI assets across workspaces.
2. Why should organizations migrate to Unity Catalog?
Organizations migrate to Unity Catalog to achieve centralized governance, fine-grained access control, improved security, and better compliance across their data estate.
3. What are the key steps in Unity Catalog migration?
Key steps include:
- Creating external locations and storage credentials
- Migrating managed/external tables
- Updating mount points
- Refactoring notebook code
- Configuring permissions and access controls
4. What is the difference between managed and external tables in Unity Catalog?
Managed tables are fully controlled by Databricks, including both data and metadata, whereas external tables only manage metadata and reference data stored in external storage (like a data lake).
5. Do you need to move data when migrating to Unity Catalog?
Not always. Data movement is only required when migrating managed tables. External tables can continue to use the same underlying data lake storage.

