
 LinkedIn
LinkedIn
It is important to understand the different features enabled for organizations through implementing Unity Catalog. In this section, we deep dive into the provisioning of users and groups, the use of external location to access objects in the datalake, how object level access works, how to enable row level and column level security, visibility into the access through Unity Catalog information schema and how to get end to end lineage through Unity Catalog.
Data Governance using Unity Catalog
One of the reasons for deploying legacy workspaces to Unity Catalog is its strong data governance capabilities.
Before Unity Catalog, data governance was siloed and hard to maintain, causing inefficiencies and non-realization of the enterprise’s data sets. This blog explains how we can enable data governance through Unity Catalog in different areas.
1) Provision of users and groups in Unity Catalog:
Prior to Unity Catalog and administration console, groups were assigned to workspaces and managed within the workspace. While there was an ability to sync up users and groups through SCIM in the workspace, the management and assignment were federated.
It was hard to know which user/group had access to which workspaces and assign new users/groups to the workspaces once the number of workspaces started to increase. Imagine an organization with more than 100 workspaces to govern and provide access that makes it difficult to manage and govern.
The new Databricks administration console enables centralized access of users/groups to the workspace without locally managing them in the workspace. A SCIM connector can be set up to sync required users/groups to the admin console.
Once the user/groups are available in the console, the Databricks Unity Catalog workspaces can be assigned appropriate user/groups from the console.
Please note that existing groups will continue to exist if a workspace is converted from non-Unity Catalog to Unity Catalog workspace for backward compatibility; however, it is suggested to remove the local groups and provision access through the administration console to enable better Databricks data governance of the workspace.
2) Accessing data in datalake through external locations:
One of the biggest pain points in non-Unity Catalog workspaces was using mount points to access the datalake. Mountpoints are used to mount the datalake storage to Databricks workspaces with authentication through principals, account keys or SAS keys.
The mount point is used to build ETL data pipelines to carry out read, transform, and write operations. The mount point is available at the workspace level and cannot be secured to be used by certain users/groups/principals. It means that any user/group with access to the workspace with a mount point to write to datalake has access to modify data in datalake.
This can be a significant governance issue as users with access to the workspace, which can write to datalake, can even delete all data in the datalake through dbuitls.fs.rm command.
The only way to control access is to build a separate workspace for the user group with a mount point that has read-only access to the workspace. The principal of the mount point is given read-only access to data that the user group is supposed to access. The other way was to use pass through cluster where security then must be configured in the datalake.
These options in most cases, are not practical to implement since they create workspace per user group OR cluster per user.
Unity Catalog overcomes these issues through the usage of external locations. Databricks External Locations are objects that combine a cloud storage path with a Storage Credential that can be used to access the location.
External Locations are similar to a mount point, created using storage credentials (created during metastore setup), except the access can now be controlled through roles to the user groups. External locations can be set at a container or folder level and access can be granted to READ, WRITE, etc., to the external location.
Please note that external locations should be non-overlapping with other external locations. For example, if an external location is created at the container level, then another external location cannot be created in a folder in the container.
In our experience, we suggest creating an external location by container or sensitive folder to segregate access.
In Dev, the developer group working on an application is given access to a particular external location, which they need to access to create their ETL pipelines.
In Production, a service principal is created that has read and write access to external locations to perform ETL operations and write to delta tables.
Please note Unity Catalog does not support mount points, which means that the existing Databricks notebooks that use mount points need to be modified to use external locations to access data.
Learn how to unlock new business value with Databricks Unity Catalog & Tredence UnityGO!
3) Object level access in Databricks Unity Catalog:
One of the strongest drivers to leverage data governance with Unity Catalog is the object-level access to Delta tables, which is now centralized and managed through Unity Catalog.
Prior to Unity Catalog, external metadata tables were required to be created in Databricks workspace, which is local to the workspace, and access to be set up for user groups through table ACLs. But these are local to the workspace. Suppose a user has access to another workspace. In that case, the same access needs to be configured again for the user, which makes it practically impossible to govern access at the Databricks table level.
With a centralized metastore, where all objects are, it enables centrally managing access to data for users/groups and enables access to the right data to the right user/group. It enables fine-grain access to data and objects in Unity Catalog.
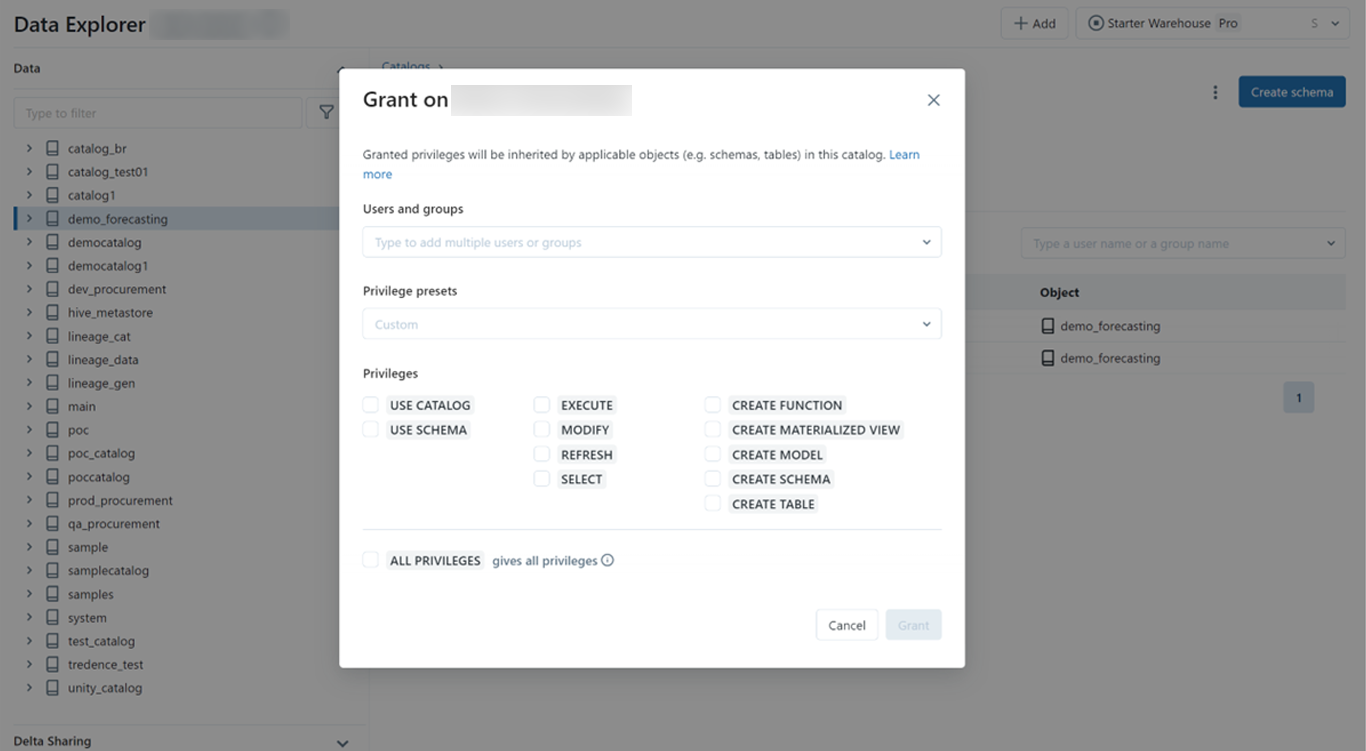
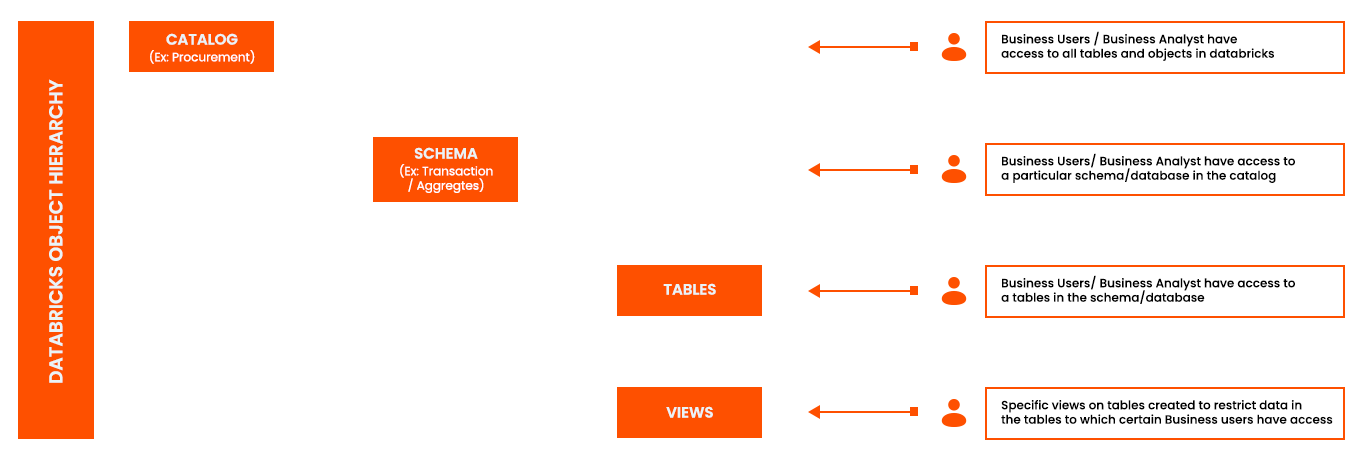
Access can be provisioned at the catalog level, schema level or object (tables and view) level as shown below.
Below is how access can be provisioned from Databricks UI below
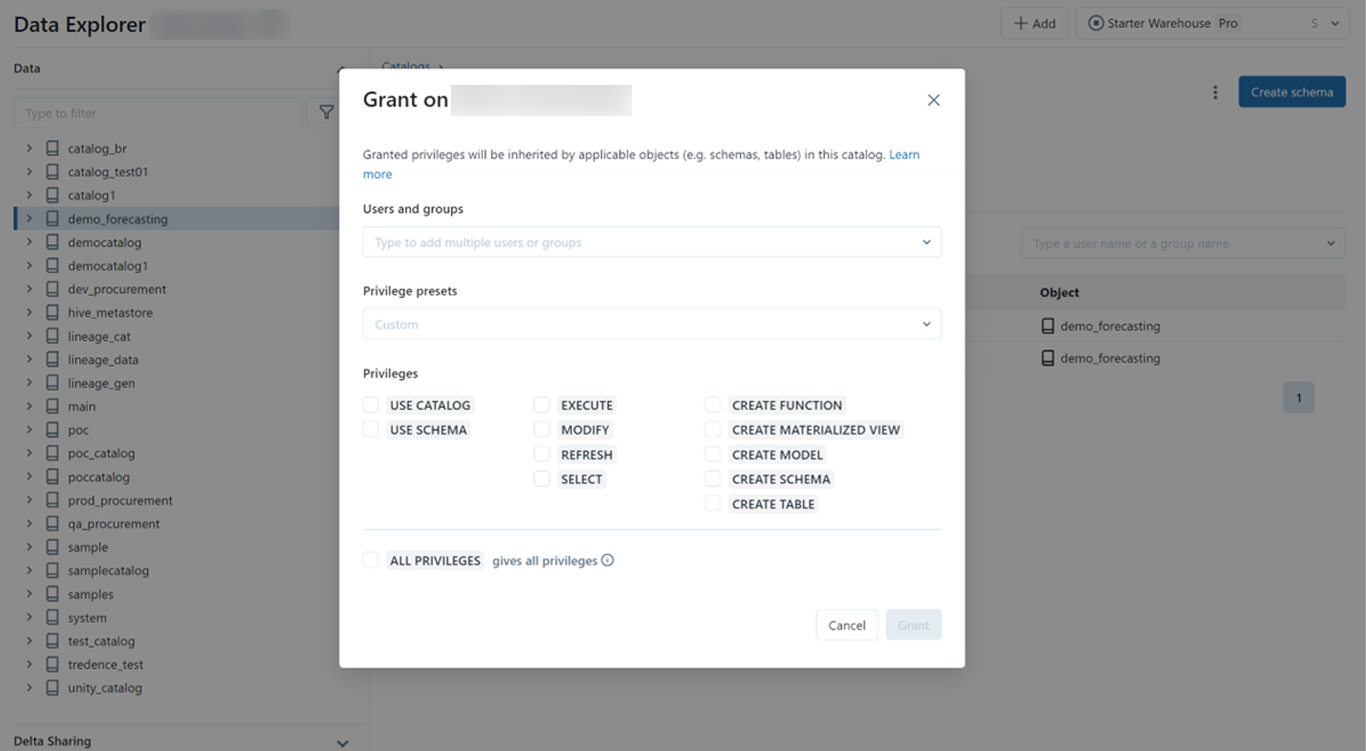
Access can be provisioned at the catalog, schema or object level and permissions trickle down to the next level. If access is provisioned at the schema or object level, it is necessary to provide the “use catalog” privilege to the user/group to enable viewing the catalog.
Please note that the above is also possible programmatically through spark SQL queries.
4) Row Level and Column Level Security in Unity Catalog:
Databricks SQL is a great tool for ad-hoc analysis, querying the delta lake tables in Unity Catalog. We can also build dashboards as part of Databricks SQL that are built on top of Delta Tables. Databricks SQL is typically used by business analysts with SQL skills who need access to data.
Although it is possible to control access at the object level through Unity Catalog object-level security, it may also be needed to secure data at column and row levels.
An example of column-level security is PII data like first name, last name, email ID, phone number, etc., which should not be visible to any data analyst.
An example of row-level security is only certain product brands and geographies should be seen by a business group.
Unity Catalog enables the security of both column-level and row-level data through the use of the is_account_group_member function. This is a function that enables securing columns and rows based on the group the user belongs to.
To build column-level security, tables having sensitive data can be REDACTED for all users except for certain groups by building a Databricks view and using the is_account_group_member. Below is a code snippet of the view that uses column-level security.
Select
first_name,
position,
case when (is_account_group_member(‘finance’) then salary else ‘REDACTED’ end as salary
from employee.
Once the view is created, access to the view can be given to all relevant groups, but it is only the finance group that can see the actual salary of an employee.
To build row-level security, we can create a metadata table that stores the object name, column name on which row-level security needs to be applied, value on which access is to be provided and groups that can access the values. Once we have the metadata table created, the table on which the row level security needs to be applied is to be joined with the metadata table and is_account_group_member is used to filter out the rows based on group access.
Example:
Select * from (
select s.grp_name, p.* from product p, security.default.rls_security s where p.brand = s.value
and s.object_name = ‘product_dim’ and s.col = 'Brand')
where is_account_group_member(grp_name)
Once we can create this as a view, access can be granted to the relevant groups, but only certain groups will be able to access the data of brands to which they are configured for access in the metadata table.
5) Visibility of access to Unity Catalog objects through information schema:
Databricks’ Unity Catalog enables logging of access metadata in an information schema.
The information schema is available under each catalog as a separate schema that stores system tables for logging access and object metadata.
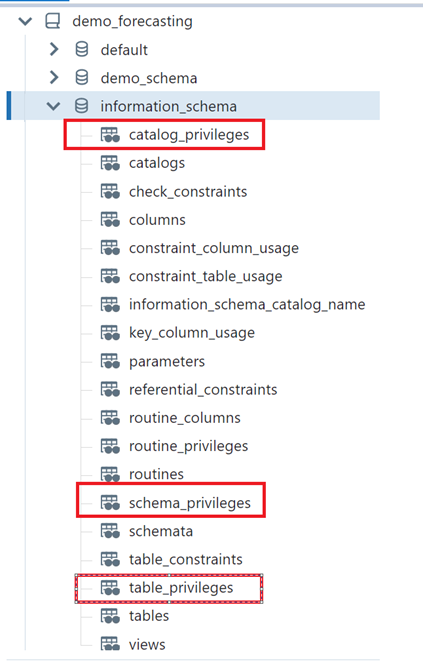
The above-highlighted tables give details of who has what access to which objects in the Unity Catalog. For example, which grantor has provided access to which grantee with privilege_type.
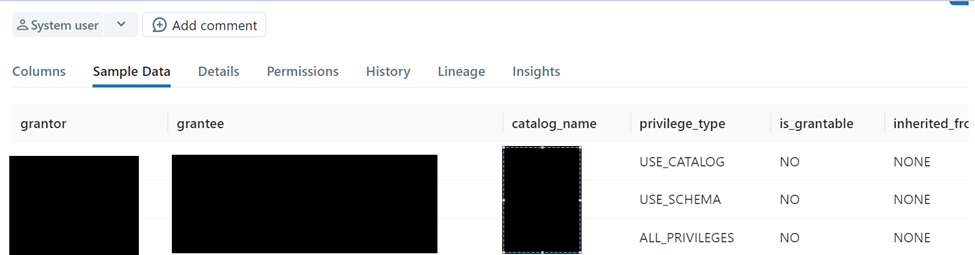
Similarly, we have tables that provide details of access to schema and objects and type of privileges to users. The information schema can be queried using SQL, and a report can be created to view access to objects and sensitive data, which helps govern access to the data.
6) Data Lineage in Unity Catalog:
Data Lineage in Databricks was limited before Unity Catalog; with many notebooks and multiple objects created in Databricks it was extremely difficult to track the lineage of notebooks that populate the table and the upstream and downstream linkages to the tables.
With Unity Catalog, object-level lineage comes out of the box without any additional configuration. By default, lineage per object is tracked in Databricks, which can be seen through Databricks UI or exported out of Databricks as a file that can be viewed in an external tool.
Below is an example of how lineage information is displayed in Databricks UI:
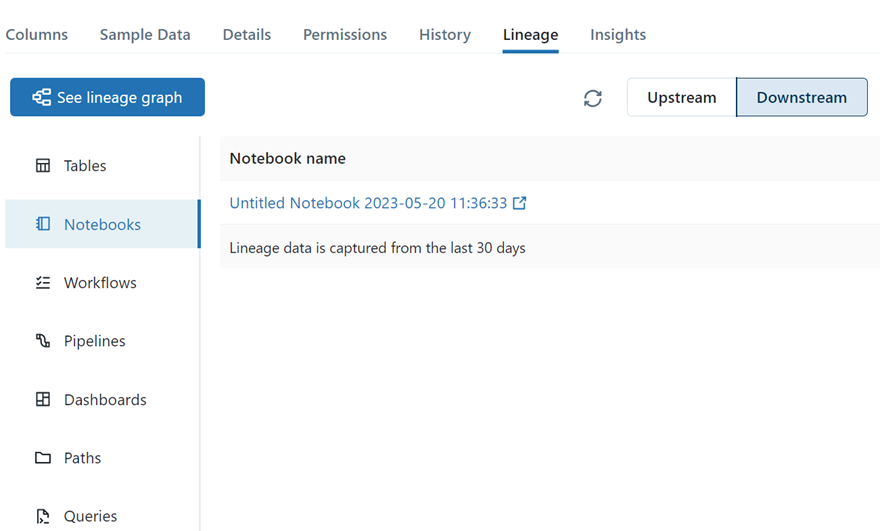
Below is an example that shows a lineage graph of data from source to bronze, silver and gold layers in Databricks. Intermediate views can also be seen as part of lineage.

This is extremely powerful as we can now understand the impact of an object change on downstream objects. Column-level lineage is also available as part of the graph.
7) Delta sharing in Unity Catalog:
A big advantage of using Unity Catalog is that now you can share objects in Unity Catalog with other recipients inside or outside your organization through Delta Sharing.
Delta Sharing is an open protocol developed by Databricks for secure data sharing with other organizations regardless of the computing platforms they use. Databricks builds Delta Sharing into its Unity Catalog data governance platform, enabling a Databricks user, called a data provider, to share data with a person or group outside of their organization, called a data recipient.
This means that if you have multiple metastore in different regions, you can enable access of data from one metastore to another through delta sharing.
The way it works is in your source Databricks metastore, you can create a share, add objects to the share, add recipients and grant appropriate access to recipients on the share.
Once enabled, a URL is created, which helps download a profile file on the recipient side, which has the URL of the delta sharing server and bearer token, which can be used to access the objects in the share.
This functionality is not limited only to Databricks but also across other technologies like Power BI, Spark, or Pandas. For example, in Power BI there is already a delta share connector which uses information from the profile file to connect to the Databricks object.
It is an easy way to share data within and outside an organization. This enables organizations to build a data mesh architecture where data can be shared across multiple domains through delta sharing protocol.
Now that you have a detailed overview of data governance solution with Unity Catalog. Don’t forget to watch this space for the next chapter that talks about migrating to Unity Catalog.

