If ‘Data is the new oil’, then good quality data must be treated like Gold!
Good quality data is extremely important as it directly impacts business insights and this could be in the form of structured data sources like Customer, Supplier, Product etc. or unstructured data sources like sensors and logs. Traditional rule-based methods to manage data quality is no longer efficient as the rule-based logic cannot keep up with the constantly changing data sources/structures. Machine learning-based Data Quality Management solutions are the need of the hour as they can learn with time and can help in identifying non-obvious data anomalies.
Sancus
Sancus is Tredence’s proprietary machine learning-based Data Quality Management solution that delivers reliable data to customers. Some of the key features of Sancus include:
- Data ingestion from diverse sources
- Data Cleanse/De-dupe/Validation
- Data Enrichment
- Data Hierarchy Creation
- Data Quality monitoring dashboards with configurable metrics and alerts
- Active learning-based feedback loop for users to pass feedback
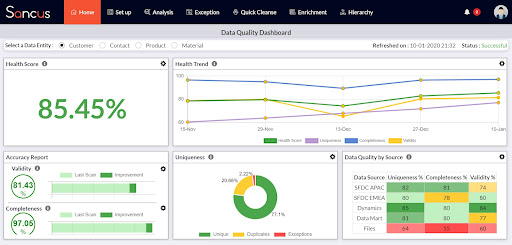
Figure 1: Snapshot of Sancus’s Data Quality Dashboard
Sancus’s web application is built on Angular and Node JS. It uses Spark’s distributed framework and Spark’s machine learning libraries to process the data. The Spark engine and machine learning model management framework are integral parts of the solution and after evaluating multiple products, we decided to build our architecture on Azure Databricks.
Why Azure Databricks?
Sancus previously ran on HDInsight, but after a closer look at Databricks, we made the decision to migrate our solution to Azure Databricks. There were a few key reasons why:
- Collaboration: Databricks has enabled our data scientists, business analysts, and data engineers to work together in ways they were not able to before. Co-authoring on the same notebook in real-time while tracking changes with detailed revision history has helped in better collaboration between the teams
- Performance: Along with reliable data, processing speed, cost efficiency, data security and end to end automation are some of the key expectations from Sancus and Azure Databricks has helped us to meet all the expectations. Cluster spin up time in Azure Databricks is very fast and on an average, we process more 100K rows in less than 15 mins using D12_V2 node type. Databrick’s faster processing time helps in reducing cost and it can seamlessly integrate with Azure components like Data Factory, Azure SQL Database, Blob storage and Azure Active Directory security. Optimized auto scaling has also helped us to save cost and use the cluster resources more efficiently
- Model Management & MLFlow: Sancus uses Databricks’s MLflow for machine learning model management. MLflow’s tracking component is used extensively to track metrics like Data Completeness, Data Validity and Data Uniqueness. The entire PySpark code is packaged using MLflow Projects and MLflow Models help in running machine learning models built on Spark MLlib and sklearn. Experiment tracking is streamlined with an interactive UI and MLflow takes care of model deployments using self-contained Docker images
Good quality data is the building block for a lot of business insights. Sancus has not only helped customers to improve their data quality but has in-turn also helped them to gain priceless business insights by solving real life business problems like Lead Prioritization, Whitespace Identification, Freight Spend Audit, Automated Document Reconciliation, Supplier Rationalization, Product Hierarchy creation and many more. Collaboration with Databricks has greatly helped us to develop Sancus as a data quality and insights discovery solution.


