
 LinkedIn
LinkedIn
Introduction
Transfer learning, as the name suggests, involves transferring knowledge gained by a model during its training process. In the context of deep learning, this typically refers to transferring the learned weights of a model. Let’s illustrate this concept with an example:
Imagine a model that has been trained on a dataset containing images of people and cars. Throughout its training, the model has learned representations of what a general person looks like and what a general car looks like. These learned representations are captured in the model’s weights.
Now, when we want to use this model to distinguish between images of people and cars in a new dataset, we can leverage its trained weights. By sending an image through the model, it utilizes its learned features to predict whether the image contains a person or a car.
However, consider a scenario where we want to differentiate between various types of cars and determine which car belongs to which company. In such cases, we can apply transfer learning by taking the pre-trained model (in this case, the model trained on people and cars), freezing its weights to preserve the learned features, and then training it on a new dataset containing different classes, such as specific car types.
This way, the model builds on its existing knowledge of general features but adapts to the nuances of the new classes. Transfer learning proves beneficial as it allows us to leverage pre-existing knowledge without starting the training process from scratch, especially in cases where datasets for specific tasks may be limited.
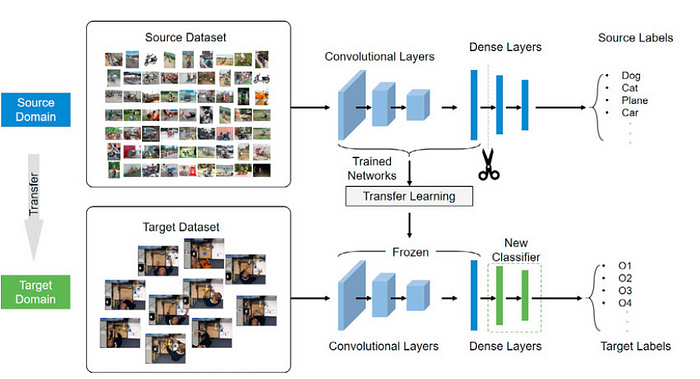
What is Transfer Learning?
Transfer learning reuses pre-trained models on new but similar tasks, reducing training time and improving accuracy. It's highly effective in domains with limited labeled data like healthcare and NLP.
How we can utilize transfer learning -
Let’s consider VGG16 pretrained architecture you can see before freezing the network all the parameters of model is unfreezed-
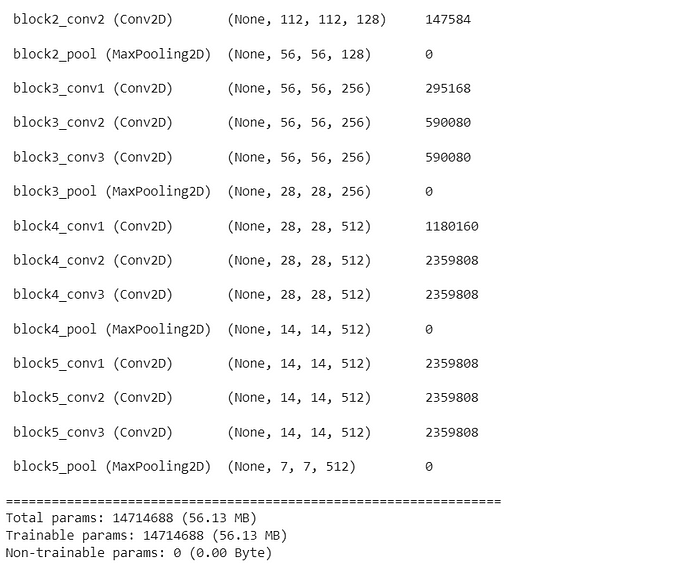
VGG16 model architecture
But to utilizes it’s learned features we have to freeze the trainable parameters first-

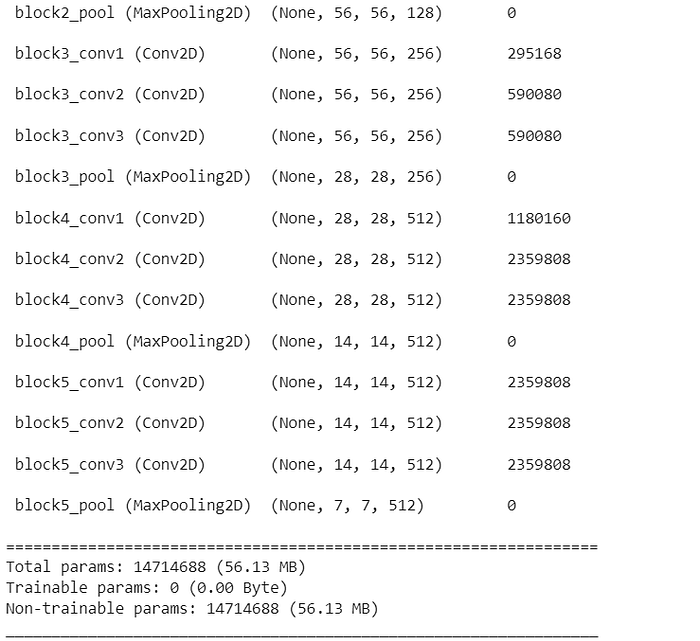
You can see non trainable params increased from 0 to 14714688 parameters.
Fine-tuning is a process through which we adapt a pre-trained model to a new task or dataset. There are various ways to perform fine-tuning, and I’ll outline a few approaches:
Replacing the Head Layer:
- One common fine-tuning method involves replacing the head layer of the original model. Suppose the original model was trained on a dataset with 64 classes, but our new task requires training on only 5 classes. In this case, we can replace the last layer of the network with a new layer that accommodates the 5 classes. Importantly, we freeze the weights of the previous layers, preserving the knowledge gained during the initial training.


You can see once we change the last head layer of vgg16 we have some trainable parameters . The parameters here are the weight matrix.
Adding a New Dense Network:
- Another approach to fine-tuning is to add a new dense network and replace the head of the pre-trained model. This allows for greater flexibility, especially when the new task involves different architectures or class distributions. The added dense network can capture task-specific features while leveraging the pre-existing knowledge in the rest of the model.
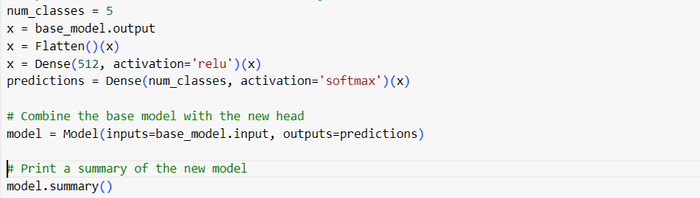

You can see we have added one more dense network before changing the head network and numbers of the trainable parameters increased to 12848133
Unfreezing Original Layers:
- One more way of fine-tuning strategy involves unfreezing some of the original layers of the pre-trained network. Instead of freezing all previous layers, we selectively unfreeze specific layers to allow the model to learn task-specific features while retaining the general knowledge acquired during the initial training. This method is particularly useful when the new dataset is significantly different from the original training data.
While learning about fine-tuning, it’s crucial to distinguish it from retraining. In fine-tuning, no additional knowledge is imparted to the model. Let’s consider a scenario where we already have a model proficient at recognizing cars in general. Fine-tuning would then involve taking that model and refining its performance on a specific dataset of car images. This process allows the model to adapt to variations in lighting, angles, or backgrounds, making it more specialized for the task.
However, if we want to expand the model’s capabilities to recognize other objects, such as bicycles or buses, we need to undertake retraining. In the context of machine learning and deep learning, retraining refers to the process of training a model again from scratch or with minimal initial knowledge. Unlike fine-tuning, which involves taking a pre-trained model and adapting it to a specific task or dataset, retraining means initiating the training process with a fresh, untrained model or one with randomly initialized weights.
In short, while fine-tuning enhances the model’s performance for a specific domain, retraining allows the model to acquire entirely new knowledge and skills, making it versatile across different object categories
Augmentation Techniques
After training a model, it is crucial to enhance its generalization performance, and one effective approach is the utilization of Data Augmentation techniques, various augmentation techniques are available, each serving specific purposes based on our requirements. It is essential to comprehend these techniques and apply them.
Let’s explore a few common Data Augmentation techniques :
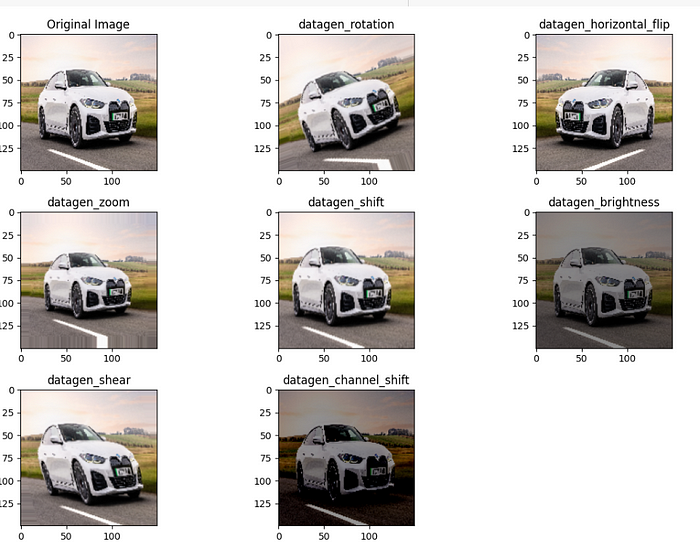
Image Rotation :
Rotation augmentation helps the model generalize better to variations in object orientations. It makes the model more robust to images where the objects may be tilted or rotated.
Horizontal Flip:
Horizontal flip introduces variability by mirroring images. It can help the model learn invariant features and improves generalization. However, it might not be suitable for tasks where the left-right orientation carries important information.
Zoom:
Zoom augmentation helps the model handle variations in object sizes. It is beneficial when objects in the images may be closer or farther away, ensuring the model is not overly sensitive to a specific scale.
Brightness:
Brightness adjustment allows the model to learn features under different lighting conditions, making it more robust to images with diverse illumination levels.
Shear Transformation:
Shear transformation introduces geometric diversity, making the model more resilient to images where objects may be sheared or distorted.
Shifting:
Shifting the width and height introduces spatial variations. This is helpful when the location of objects within the image may vary, making the model more adaptable to different object placements.
Channel shift:
Channel shift introduces color variations, aiding the model in learning to recognize objects under different color schemes.
Some Advance data Augmentation techniques:
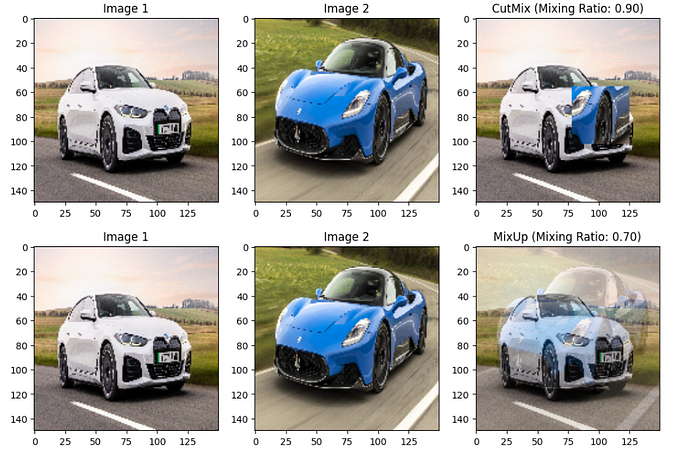
CutMix:
CutMix involves cutting a portion of one image and pasting it onto another image, creating a new training example.
Let’s say we have two images ,image 1 and image 2 and lambda ., so augmented image and label will become:
Mixed_image = image2(i,j) if(i,j) belongs to cut region else image1(i,j)
Label_mixed = y1 * lambda + (1-y)* lambda
Lambda is a mixing ratio, often sampled from a beta distribution. It determines how much influence each original image has in the final mixed image
- CutMix is particularly useful when dealing with datasets where objects are sparsely distributed within the image and If the task involves object localization, CutMix encourages the model to learn features that are robust to partial occlusions and improves localization accuracy.
- CutMix acts as a regularization technique, preventing the model from overfitting to specific object configurations in the training set.
MixUp:
MixUp involves blending two images and their corresponding labels to create a new training example.
Let’s say we have two images ,image 1 and image 2 and lambda ., so augmented image and label will become:
Mixed_image = lambda * image 1 + (1-lambda) * image 2
Label_mixed = y1 * lambda + (1-y)* lambda.
- MixUp encourages the model to learn from the combined features of both images, improving generalization and acts as a regularization technique, preventing the model from memorizing specific training samples.

