
When deploying ML projects, the Kubernetes-powered Kubeflow ecosystem has a good shot at tackling scaling and infrastructure dependencies. It is the best fit for Trade Promo Effectiveness (TPE) models, which run at scale with incremental data loads. If the entire project runs in a single cloud, infrastructure and scalability challenges can be eliminated to an extent. But it is estimated that around 80% of enterprises are multi-cloud, and the infrastructure differences between these two systems pose a challenge. Kubernetes and containers provide the abstraction needed to run the same ML workflow in all these environments and scale seamlessly.
Challenges with Conventional TPE Models
Building and deploying TPE models to production is critical to a CPG firm. Here is why TPE models can be challenging during deployment:
- With each refresh, the incremental data load increases, hence increasing the intersections while generating features and training.
- TPE models are generally time-series-based models that can forecast sales. Thus, sales figures should be accurate enough to measure the impact of promotion and help the businesses make strategic decisions on their promotion spend.
- Data practitioners need to experiment with different time-series models for each SKU to obtain accurate forecasts and determine the best model to deploy in production.
- The complexity of the solution increases further as businesses extend their predictions to different regions. To give you a snapshot of the scale of the predictions – let’s say there are 100,000 SKUs. Each model entering production is automatically selected by comparing the RMSE values of two different models
- Each model will also contain external regressors to generate feature vectors using which the models are trained and validated.
To support such large-scale and incremental data loads, we should build and deploy the TPE pipeline using an auto-scalable framework to support parallelization. This is where Kubeflow weighs in. It is built to handle the auto-scaling of deployed pipelines and offers customization to organize our workflows. Let’s see how we can implement an optimized TPE workflow using Kubeflow.
Optimized TPE Workflow With Kubeflow
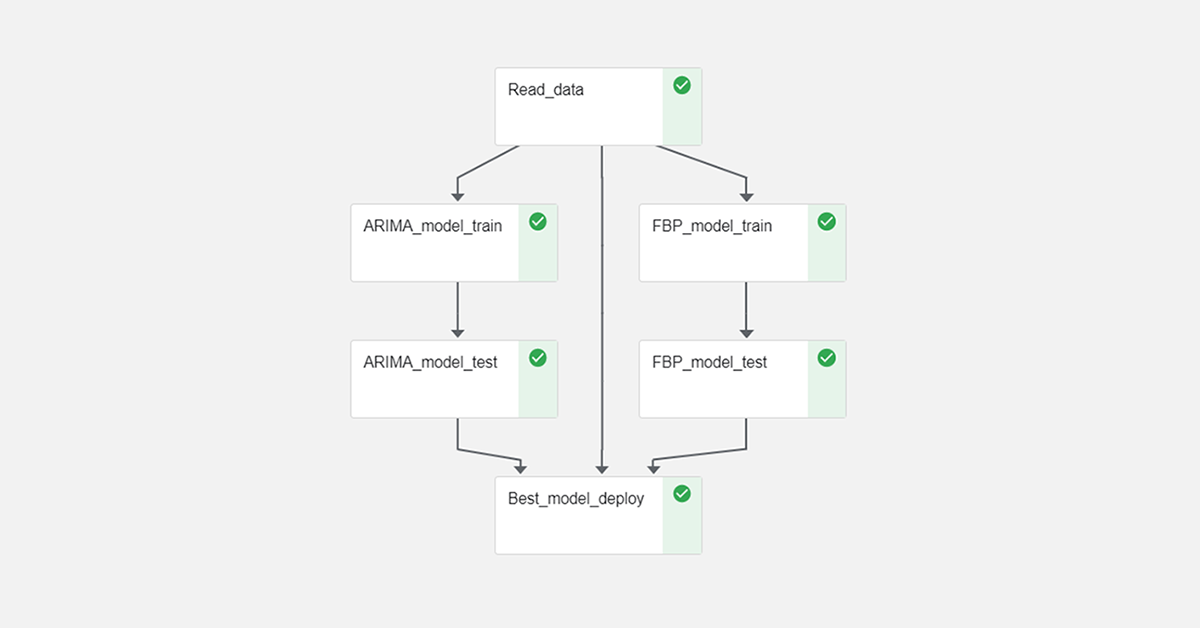
The workflow contains four components from the data ingestion module to the deployment module.
- The data for prediction is stored in an SQL table and Azure Blob; the Read_data module reads the data from these locations and sends it to the next stage.
- The following modules are the feature generation and prediction modules. Since we are selecting the best model to predict for a given SKU, we use FB Prophet and ARIMA models for the same SKU to compete against each other. In the Best_model_deploy module, the best model for an SKU is chosen based on RMSE values.
- Post these modules, the model is validated in FBP_model_test and ARIMA_model_test on different model performance metrics.
- Finally, in the Best_model_deploy stage, both model results are compared, and the best model for each SKU is deployed into production.
The feature generation and model training for FB Prophet and ARIMA models are independent of each other. To have an optimized workflow, we can parallelize the workflow. ARIMA_model_train and FBP_model_train use the Read_data module’s output in parallel where feature generation and model training happens. Similarly, FBP_model_test and ARIMA_model_test also run in parallel. The flows can be organized by connecting the output of each step to the next step. The workflows can be reorganized by using “.after” method of the Kubeflow pipeline. The real-time run status can be tracked in Kubeflow UI. The Parallel workflow runtime of this TPE project is about 33.3% faster than sequential workflow. The figure below shows the TPE pipeline using Kubeflow – a parallel workflow.
Auto-Scaling: The Trump Card of Kubeflow This TPE pipeline is scalable for the incremental loads that come at regular model refresh. This is due to two factors:
- The parallel workflow is optimized for choosing the best model, and the runtime of the pipeline is drastically reduced. Kubeflow can handle parallelization by vertically scaling the pods on which the pipeline runs. Its heavy customization makes this possible.
- For data of ~400,000 data points and ~100,000 incremental loads, auto-scaling (both horizontal and vertical) is easily enabled in Kubernetes pods on which the pipeline runs.
Kubeflow Can Automate & Scale CPG’s Complex ML Models In conclusion, Kubeflow pipelines are a great open-source tool to automate complex analytics models and scale them exponentially. It can be heavily optimized and customized to suit our needs and auto-scaled without changing the infrastructure. It also exhibits dominance over its proprietary competitors like AWS SageMaker and other open-source projects like Airflow. We are excited to announce the launch of the community version of Tredence’s ML Works. Now, you can try ML Works for free. It is an enterprise-grade MLOps monitoring platform designed to monitor the health of ML models in production. Explore the platform with your model objects, training & test datasets, or leverage the pre-loaded projects to navigate the platform’s unique capabilities and understand your model better with ML Works’ Drift and Explainability features. If you want a personalized Demo or have customization needs for your organization, you can directly reach out to the ML Works team at mlworks@tredence.com. Register and explore Drift and Explainability in ML Works today!!
BONUS
Sneak peek of ML Works.

AUTHOR - FOLLOW
Jayasurya Ragupathi
Business Analyst
Topic Tags

Detailed Case Study
Driving insights democratization for a $15B retailer with an enterprise data strategy
Learn how a Tredence client integrated all its data into a single data lake with our 4-phase migration approach, saving $50K/month! Reach out to us to know more.

Detailed Case Study
MIGRATING LEGACY APPLICATIONS TO A MODERN SUPPLY CHAIN PLATFORM FOR A LEADING $15 BILLION WATER, SANITATION, AND INFECTION PREVENTION SOLUTIONS PROVIDER
Learn how a Tredence client integrated all its data into a single data lake with our 4-phase migration approach, saving $50K/month! Reach out to us to know more.
Next Topic
Understanding the value of artificial intelligence solutions in your business
Next Topic





