Today organizations are increasingly data driven. With technology advancements and storage costs declining, the volume of data is growing exponentially by the day. While data storage is no longer a concern, managing the acquired data has become a problem.
Data governance is critical to every organization, yet not everyone has successfully implemented a good data governance strategy. According to Gartner, “Every year, poor data quality costs organizations an average of $12.9 million. Besides the immediate impact on revenue, over the long-term, poor-quality data increases the complexity of data ecosystems and leads to poor decision making.”
There are two components of data governance: data catalog and data lineage.
According to Oracle, one of the world’s largest database providers, a data catalog is an ‘organized inventory of data assets’ that uses metadata to help organizations manage their data." In contrast, data lineage is how these data assets are created and connected with each other so an audit trail can be formed.
These concepts sound straightforward, but why exactly are organizations not doing data governance or not doing it correctly?
Challenges firms face in enhancing data governance capabilities:
- It is not easy to keep a single source of the truth
Organizations can easily create duplicates of their data. If this data gets synced back to the data catalog tool, it can generate confusion for users who don’t know which version of the table is the latest.
is not easy to keep up with the ever-growing amount of data. New feeds and ETL processes make it hard to manage data definitions. Most of the time, organizations lack a dedicated team to manage metadata.
- Multiple developers work on a project, and they work in a silo without knowing how others use the data.
In order to create a data audit trail, one needs to understand how the data is being utilized. Without code standardization or communications between developers, code parsing tools are useless and won’t generate the linkage between data.
Code evolves faster than documentation can keep up
Like data growth, code also grows exponentially, especially in a large team. If the code grows without any standardization or automated way to extract the lineage that can accommodate different favor of development, it will be impossible to maintain a lineage diagram.
When choosing data catalog tools, it is important to consider the following factors:
- The tool conforms to industry standards
- It does not require a lot of developer intervention
- It can operate with other existing tools
- Tight integration with the code
Databricks is known for its excellence in data processing. Recently, Databricks released new frameworks to make data governance easier and more efficient. Databrick’s Delta Live Tables (DLT) is a framework created by Databricks to make data cataloging and lineaging within the Databricks ecosystem, and the tool also conform to industry standards.
Delta Live Tables is not just a data governance tool; it also supports many distinctive features like streaming tables, audit logs as well as QA and ETL framework, among other things. However, in this post, we will focus on the data governance aspect of DLT.
Delta Live Tables support both SQL and Python. To take advantage of this framework, there is a specific syntax that needs to be followed.
To create a Delta Live Table in SQL, the only thing that needs to change is to use the keyword LIVE as follows:
The syntax for creating a streaming pipeline is as follows:
@dlt.table
def filtered_data():
return dlt.read("taxi_raw").where(...)
Python's syntax is more complex; however, by simply adding a declaration, you can make it simpler:
So, what is the magic behind this LIVE keyword if we are not streaming?
Delta Live Tables go far beyond streaming.
Features of Delta Live Tables
- Continuous or triggered pipeline – Whether you are running a streaming job or just doing a one-time load, you can use Delta Live Tables.
Validations – Setting the expectations right within the table definition, so there is no need to get another validation pipeline set up. An example of expectations is “revenue is greater than 0.” You can choose to drop or retain the records or even halt the pipeline. - Data lineage – You no longer need a separate tool to generate a lineage diagram. Instead, you can easily migrate the SQL or Python notebook to DLT format and take advantage of the lineage that comes with the data pipeline. It will generate by itself without needing to onboard these to a tool.
- ‘Develop and Production’ mode gives you the flexibility to test your code without impacting production jobs.
- Enhanced auto-scaling is an advanced scaling mechanism that will allow you to start or stop a cluster automatically, resulting in more savings.
- Logging and monitoring – DLT comes with a logging and monitoring dashboard that allows you to track job status step by step without having to create other monitoring tools.
Let us look at a retail sales pipeline developed by Databricks:
https://github.com/databricks/delta-live-tables-notebooks/blob/main/sql/Retail%20Sales.sql
The example above highlights four features:
- Streaming pipeline
- Data validation
- Data lineage
- Validation dashboard
-
- Streaming Pipeline
The syntax for creating a streaming pipeline is as follows:
CREATE STREAMING LIVE TABLE sales_orders_raw
COMMENT "The raw sales orders, ingested from /databricks-datasets."
TBLPROPERTIES ("myCompanyPipeline.quality" = "bronze")
AS
SELECT * FROM cloud_files("/databricks-datasets/retail-org/sales_orders/", "json", map("cloudFiles.inferColumnTypes", "true"))
This raw pipeline is simply trying to stream the JSON files from the specified location. As a result, it is now simpler to build a streaming pipeline using DLT. - Data Validation
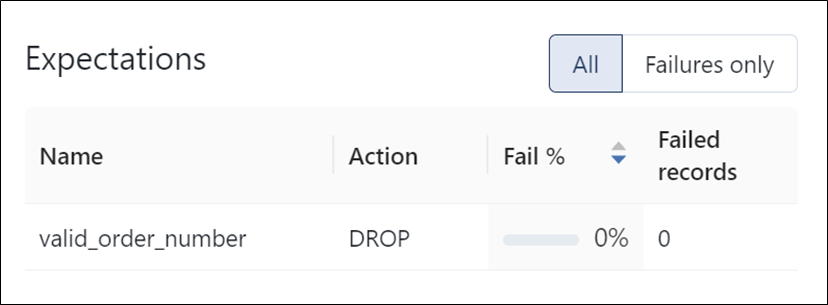
The next step is to perform data clean-up. The traditional ETL requires separate steps for error handling and data validation. As a result, these logics will be written in the SQL query, and other developers will try to decode the purpose. In DLT, there is a descriptive way to handle these records called expectation. The syntax is as follows: - Data Lineage
A flow chart in the DLT job shows how the data move from one place to another. Therefore, there is no need to run it through another parsing tool to generate these diagrams.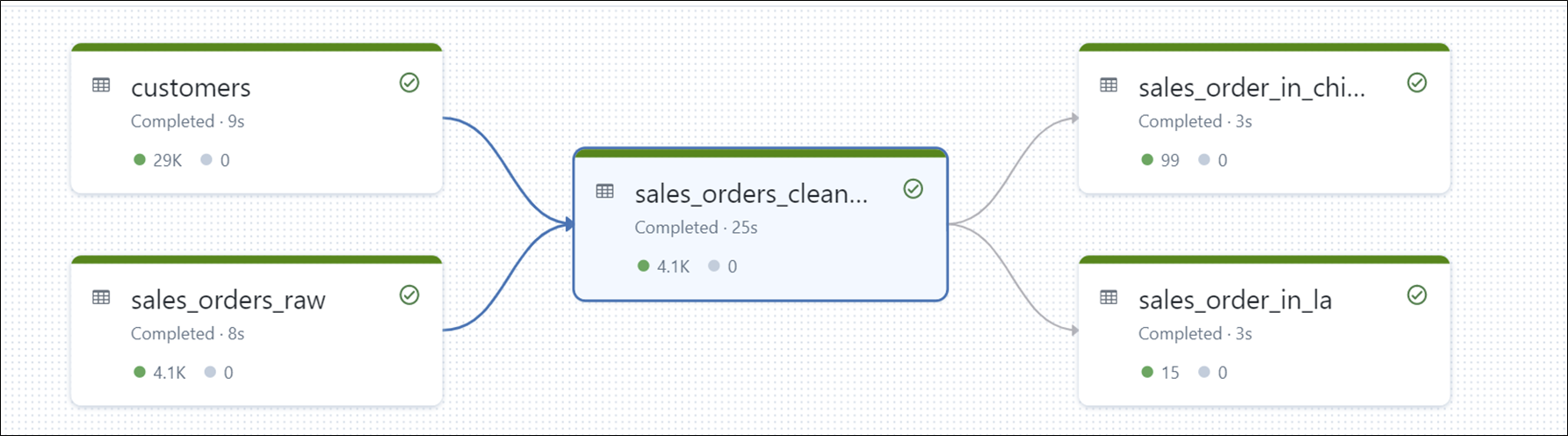
- Validation Dashboard
Each step automatically provides a summary of the expectations and data quality checks, saving time on the creation and upkeep of additional toolkits. The time needed to evaluate the code to ensure data validation is also reduced by having these available automatically.
Databricks’ Delta Live Tables Help Enterprises Enhance their Data Governance Capabilities
Data teams are constantly on the go. However, with Databricks' Delta Live Tables, they can streamline reliable data pipelines and quickly find and manage enterprise data assets across various clouds and data platforms. Additionally, they can simplify the enterprise-wide governance of data assets, both structured and unstructured.
We have illustrated how to use Databricks’ Delta Live Tables to solve issues in data governance. For technical deep dive and all features available in Delta Live Tables, click here.


