
 LinkedIn
LinkedIn
What if your IT systems could fix problems before anyone noticed them?
Imagine a world where outages don’t happen at 2 a.m., alerts don’t pile up in your inbox, and your systems quietly solve problems before users even notice. No more war rooms. No more guesswork. Just smooth, self-healing operations that run on intelligence, not brute force.
As enterprise IT grows more complex, traditional monitoring tools are falling behind. They are getting late, provoking alert storms, and looking at only a fragment of what is happening. Thus, leading IT teams are increasingly adopting AI operations or AI Ops.
AI Ops is an abbreviation for Artificial Intelligence for IT Operations. AI Ops combines machine learning, big data, and automation to revolutionize how IT teams manage, monitor, and optimize their systems. It focuses IT teams on problem-solving, not just Firefighting.
In this article, we will identify what AI Ops is, how it works, and why it is an important part of managing the complex IT environments we are operating in today.
What Is AI Ops?
AI Ops, or Artificial Intelligence in Operations, is the application of machine learning and big data to automate and enhance IT operations. It provides real-time analytics, anomaly detection, and predictive capabilities by aggregating and correlating data from multiple IT systems.
AI Ops is a shift in how IT teams approach operations. 42% of large enterprises (1,000+ employees) have already deployed AI (Source). Instead of manually sifting through logs, alerts, and metrics, it uses advanced algorithms to connect the dots at machine speed.
Here are the three foundational capabilities of AI Ops, which make IT operations efficient:
- Data-driven: It ingests data from logs, events, alerts, metrics, and traces across your IT infrastructure.
- Context-aware: It identifies patterns, correlates events, and reduces alert noise to surface root causes faster.
- Actionable: It can monitor and automate actions, provide recommendations, and also remediate incidents, all in real time.
By putting AI at the core of IT operations, it redefines the role of your teams from reactive to proactive, primarily focused on preventing issues from arising.
Why AI Ops Matters in Modern IT
IT environments today aren’t what they used to be. You’re managing cloud-native apps, hybrid infrastructure, microservices, and remote users, all generating massive volumes of real-time data. Traditional tools can’t keep up. AI Ops addresses these challenges head-on by bringing speed, scale, and intelligence to IT operations. Here’s why it’s become essential:
- Data overload is real: IT systems generate terabytes of data every day. AI Ops sifts through it to detect anomalies, surface insights, and eliminate alert fatigue.
- Speed is non-negotiable: With real-time systems and always-on services, speed has become a defining factor in IT success. AI high performers are 5× more likely to invest heavily in AI, enabling faster detection, response, and resolution (Source). This speed isn’t just operational, it’s strategic.
- Downtime is expensive: Reports estimate that for 98% of organizations, IT downtime costs an average of $100,000 per hour (Source). AI Ops helps prevent issues before they snowball.
- Modern architectures need it: Cloud, containers, and DevOps practices demand faster, more adaptive monitoring and automation. AI Ops fits perfectly into this dynamic model.
Ultimately, AI Ops monitoring driver for IT teams stays ahead of issues and enables greater productivity and overall, a better digital experience for users and customers.
How Does AI Ops Work?
AIOps platforms consolidate large, scattered IT data and transform it into real-time insights using AI analytics and automation. This leads to smarter, self-healing systems. These platforms use big data, machine learning, natural language processing (NLP), and fast AI automation to monitor, spot issues, and optimize performance quickly and at scale.
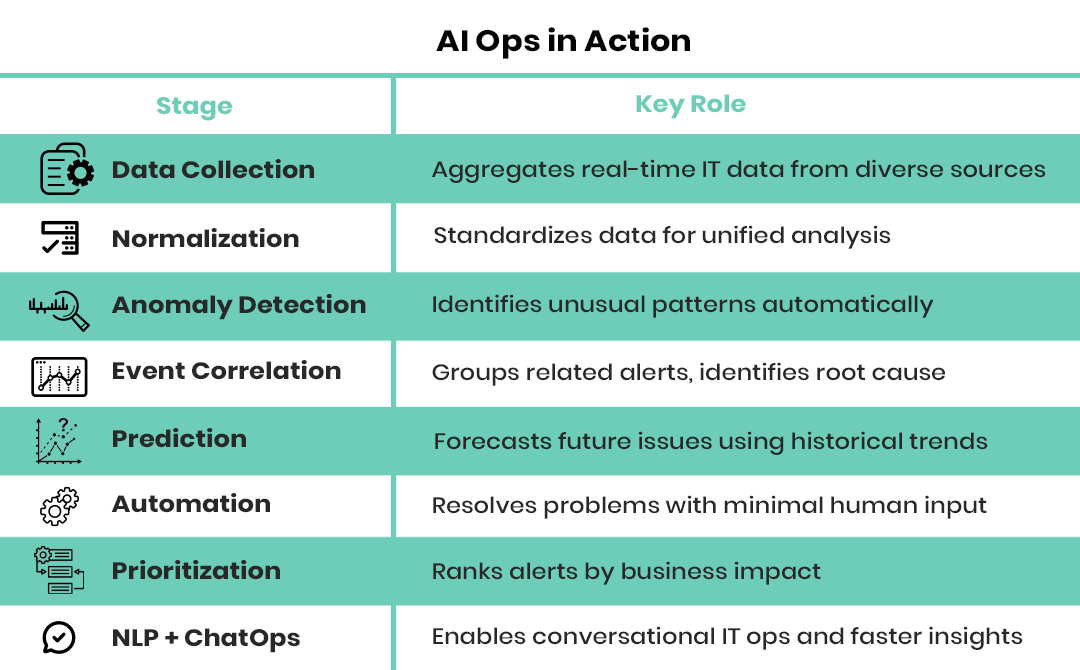
1. Data Collection Across the Stack
AI Ops starts with the ongoing collection of large amounts of operations data across your IT domain, including logs, metrics, events, traces, and configuration data. This covers everything your organization interacts with, such as servers, applications, cloud services, and users.
What data gets collected?
- Logs (system, app, network)
- Metrics (CPU usage, memory, latency, throughput)
- Events and alerts
- Traces (end-to-end request journeys)
- Tickets and incident data (from tools like ServiceNow, Jira)
- Configuration files and asset data
2. Data Ingestion and Normalization
When aggregated, the platform ingests its diverse data and returns a coherent, structured version of it. Normalization is the process of reconciling distinct schemas, aligning timestamps, and cleaning errors in order to objectively analyze and interpret data.
AI Ops platforms perform:
- Data cleansing to remove duplicates and fill missing values.
- Schema mapping to align structures across systems.
- Timestamp synchronization to maintain accurate event timelines.
This action confirms your downstream analysis is collaborative and correct in a hybrid or multi-cloud space.
3. Smart Anomaly Detection
AI Ops leverages unsupervised machine learning to initiate anomaly detection autonomously by referencing current data with historical averages. These anomalies are almost always compelling indicators of underlying system problems that need to be identified before they evolve into incidents. Early detection is possible through AIOps analytics as it will continuously learn, assess patterns and anomalies, and ultimately improve accuracy over the duration of an operation.Common examples of anomalies detected by AI Ops include:
- A sudden spike in API latency
- Traffic drops to a microservice
- Abnormal resource consumption on a Virtual Machine (VM)
4. Event Correlation & Root Cause Identification
Instead of overwhelming teams with separate alerts, AI Ops solutions correlate associated events to show a single incident, including the true root cause. This drastically cuts through alert fatigue. AI Ops solves this through topological analysis and historical pattern matching, using pattern recognition algorithms and past incident data to correlate events and identify root causes.
For example, instead of flooding your dashboard with alerts for "API timeout", "DB connection failure", and "service crash", AI Ops links them to a single root issue: database latency.
5. Predictive Analytics & Proactive Insights
One of AI Ops' most powerful features is its ability to predict incidents before they happen. By learning from past behaviors and performance trends, AI Ops forecasts risks like system crashes or resource exhaustion. By analyzing trends and past incidents, AI Ops systems forecast potential problems, like capacity saturation, application failure likelihood, and performance degradation.
A good example would be predicting CPU exhaustion in a container cluster and auto-scaling it ahead of a traffic spike during a marketing campaign.
6. Automated Remediation & Response
AI Ops can initiate workflows automatically when any issue is identified and engage any existing support solutions to log an incident, create tickets, or notify the appropriate teams. Typical automation includes restarting a failed service, redeploying cloud systems, adding/updating tickets in ITSM (IT Service Management) tools, or triggering rollbacks to a bad deployment.
The AI Ops product will also be compatible with toolsets that can use Ansible, Kubernetes, Jenkins, or Terraform to perform full-stack remediation.
7. Alert Prioritization by Business Impact
AI Ops doesn’t just detect incidents, it ranks them based on criticality. It assigns priorities based on severity, users affected, and the service impact, so everybody on the team is working on the highest risk first. For example, a slowdown that impacts the database that affects billing is prioritized higher than a database slowdown that impacts a dev testing environment. It uses business impact scoring, dependency mapping, and user behavior monitoring to prioritize the alerts.
8. Natural Language Processing (NLP) & ChatOps
Today’s AI operation platforms integrate with NLP and chatbot platforms to allow IT personnel to interact naturally through simple conversational queries. This leads to more efficient and accessible incident investigation; engineers can now simply ask, “What caused the latency spike at 2 PM?” or, “How many incidents associated with service X did we have last week?” directly into their collaboration tool.
It should also be noted that worldwide spending on AI software is estimated to rapidly increase from $124 billion in 2022 to $297 billion in 2027, meaning companies are continuously investing in intelligent conversational interfaces such as ChatOps to help develop agility, collaboration, and operational efficiencies across IT teams. (Source).
Types of AI Ops
AI Ops features various AI Ops capabilities developed for different operations-centric outcomes. Each capability serves a unique operational purpose to work toward optimizing your IT operations, from anomaly detection to automation and chat-based collaboration. Below, we list the important AI Ops capabilities and their value:
1. Event Correlation & Anomaly Detection
AI Ops leverages log files, metrics, and events to detect unexpected patterns and abnormal spikes across your entire stack, and connects unrelated signals, so your team can methodically move through the noise.
2. Predictive Analytics & Forecasting
AI Ops employs machine learning to analyze historical data around trends and resource usage, as well as systems behavior, to detect the likelihood of potential failure. This fundamental predictive capability is useful because it allows your team to take action before the failure negatively impacts the end user.
3. Automation & Orchestration
Not only can AI Ops do monitoring, but the AI in AI Ops can also trigger workflows to automatically start restarting services or scaling infrastructure without human involvement. It can also orchestrate complex, multi-system actions more smoothly as part of incident resolution.
4. ChatOps and Intelligent Chatbots
AI Ops can embed capabilities directly into team collaboration tools through ChatOps, allowing teams to resolve issues in real-time from a conversational interface. Chatbots powered by AI (intelligent chatbots) can read commands, share metrics, and even trigger fixes, without users leaving the chat interface.
AI Ops accelerates incident response by automatically diagnosing the root cause of failures through pattern recognition and dependency mapping. This eliminates the guesswork and reduces downtime.
Also Read: AI Services are Dead. Long Live AI
The Benefits of AI Ops
While AI Ops can involve smarter monitoring, the implementation of AI Ops offers fundamentally more value for organizations. It provides the real value of AI solutions in business to operationalize IT, save money, and see value across the organization. From quicker mean time to resolution to scaling to service quality, here is the value organizations are likely to see with AI Ops:
Quicker Detection and Mitigation of Issues:
AI Ops enables a proactive shift from reactive operations by automatically identifying anomalies and performing root cause analysis so that IT teams can detect issues in real time and resolve them proactively before they escalate. This shift in operation provides significant utility around reducing mean time to resolution (MTTR) and limiting the impact on service availability.
Reduced Downtime and Operational Costs:
AI Ops employs predictive analytics and automatic remediation capabilities to address issues before they lead to resource degradation and outages. The software reduces both planned and unplanned downtime with fewer critical disruptions, and also improves service-level agreements (SLA) for corporations.
Greater IT Team Productivity and Efficiency:
By filtering out the noise of non-critical alarms and automating day-to-day tasks, AI Ops enables teams to focus their time on more critical and valuable tasks. The repetitive frustration of troubleshooting is eliminated, while also speeding up decision-making. IT teams can be more responsive, agile and productive.
Optimized Decision-Making Supported by Actionable Intelligence:
AI Ops unlocks insights that would never be seen in silos of logs and systems, by observing and horizon-scanning across all domain data streams in real time. With the elevated insights made possible through data—and with guidance from experienced AI consulting partners—IT business leaders are able to make smarter, faster infrastructure decisions.
Better User Experience Through Proactive Problem Management:
AI Ops limits service disruptions and optimizes performance, thereby giving users the ability to rely on digital services on a consistent basis. When problems are resolved before users realize the problem existed, users' satisfaction and trust improve significantly.
Scalability and Adaptability in Complex Environments:
As businesses scale across hybrid and multi-cloud infrastructures, AI Ops offers the adaptability, scalability, and intelligence to scale in the right direction. It scales through increasing complexity, interfaces with modern DevOps pipelines and expands according to enterprise IT needs.
AIOps Examples and Use Cases
AI Ops isn't just a concept. Organizations across industries are seeing results by applying AIOps analytics to everything from infrastructure health to cloud spend forecasting. Here’s how leading organizations are leveraging AI Ops monitoring to stay ahead:
1. IT Infrastructure Monitoring and Management
Keeping track of everything going on in today's IT infrastructure is incredibly complicated and involves thousands of moving parts, like logs, metrics, and services, in a hybrid world. That's where AI Ops comes into play - assisting IT operations by monitoring system health, identifying anomalies in real-time, and even resolving issues autonomously, one of the most beneficial AIOps use cases in the modern IT world. This means IT teams can be proactive instead of reactive to challenges, solving problems with greater speed and less pressure.
That’s exactly what SIXT, the global mobility company, achieved with IBM Instana and Turbonomic. Instana gave them instant visibility into how services connect and perform, while Turbonomic handled the heavy lifting of resource optimization behind the scenes. The result? A 70% drop in detection and resolution time, meaning smoother digital services and fewer firefights for the IT team. Source
2. Cloud Operations and Optimization
Cloud platforms provide scale and flexibility, but if proper automation is not in place, they usually result in overspending and inefficiencies. AI Ops solves these issues by constantly monitoring resource usage, forecasting demand, and shifting workloads in real time. With intelligent optimization, organizations can manage expenses and keep performance at its peak.
One of the most practical AIOps examples is what WPP, a global marketing leader, achieved with IBM Turbonomic and Apptio Cloudability. Their AI-driven FinOps system automated over 1,000 resource resizing actions per month and enabled precise forecasting. This led to a 30% reduction in yearly cloud spend, saving $2 million in just three months, with no impact on performance. Source
3. Security Event Monitoring and Response
Security teams are flooded with alerts daily, most of which are low-impact or false positives. This overwhelms traditional Security Operations Centers (SOCs), delaying response to real threats. AI Ops changes that automate alert triage, prioritizing incidents by risk level, and enabling faster, more accurate responses.
Intezer implemented this through its Autonomous SOC platform, which uses AI to analyze and classify every incoming alert. The system has 97.7% false-positive accuracy and 93.45% true-positive accuracy, and it completed investigations in 2 minutes and 21 seconds. The degree of automation prevents the manual action of SOC analysts, allowing them to focus on high-priority threats while the low-priority daily alerts are handled with speed and accuracy. Source
4. Application Performance Management (APM)
If application performance is everything for user experience. Then AI Ops is taking application monitoring to the next level by not just monitoring how users are using an application in real-time, but predicting how users will use an application in the future, alerting teams when people are having issues before they become issues, and autonomously allocating resources to keep applications running smoothly. You can think of AI Ops like a standard proactive safety net that’s always preparing and planning for the unexpected in the background.
APIS IT, a major IT provider for the Croatian government, adopted IBM Instana and Turbonomic to strengthen its Application Performance Management (APM) strategy. Instana offered deep observability into app performance, while Turbonomic automatically reallocated resources to meet demand. The results were impressive: a 70% acceleration in resourcing decisions, 50% lower MTTR, and a 20% improvement in container utilization, all driving more reliable service delivery. Source
5. Incident and Problem Management Automation
Handling incidents on your own can be slow and error-prone behaviour, particularly in challenging IT environments where a mix of processes, tools and resources may be involved. AI Ops improves the way incidents and problems are managed by providing systems to automate the detection, classification, and remediation processes involved. This also reduces alert noise, correlates events, and provides insights on how to take action faster. Providing IT teams with actionable insights also means being able to manage incidents or act on problems more efficiently.
PagerDuty shows how effective this can be. By embedding AI Ops into their incident workflows, they automatically group related alerts, reduce noise, and eliminate alert fatigue. Their system adds context to each incident and routes it to the right team without delay, making response faster, smoother, and far more reliable—an example of highly practical AIOps use cases for ITSM. Source
6. Capacity Planning and Resource Optimization
Capacity planning presents a dilemma: too much capacity wastes money, while too little capacity leads to slow and inefficient service. AI Ops will be able to take into account historical and real-time data to forecast demand so that organizations can achieve that delicate balance. It analyzes patterns of usage, predicts capacity needs and automates decision making of where to allocate capacity to ensure that teams are as efficient as possible without overprovisioning.
The BMW Group demonstrates this with its Car2X and AIQX platforms, which use AI to make vehicles active participants in their production. These systems predict resource bottlenecks, detect anomalies in real time, and guide human operators with automated instructions. The result is faster assembly, fewer quality issues, and leaner use of infrastructure across BMW’s global production network. Source
Smarter IT Starts with AI Ops
AI Ops isn’t a concept of the future; it’s a practical, proven approach to modernizing IT operations. Today, downtime is expensive, and user expectations are higher; AI Ops can provide your IT teams the speed, accuracy, and visibility needed to stay ahead of the curve.
Each journey starts by understanding your critical challenges and ends with creating resilient, self-optimizing IT environments that innovate activity. If your systems are growing, but your tools are not, it’s time for a change.
At Tredence, we help enterprises unlock AI Ops at scale, from strategy to execution. Let’s build faster, smarter, more resilient IT together. Ready to start? Let’s talk.
FAQs
-
Can AI Ops integrate with existing IT tools and systems?
Yes, Most AIOps solutions allow for an organization to integrate to their existing IT service management (ITSM) tools, monitoring tools and/or cloud tools. The interoperability enhances an organization’s current investments by allowing for intelligent automation and analytics layers to be implemented on top of the existing systems.
-
How is AIOps different from traditional IT monitoring?
Current IT monitoring systems are predominantly reactive. They alert you to detect an issue, after the issue occurs - and in many cases they inundate the teams with these alerts. AIOps is proactive. AIOps uses AI and machine learning to identify trends/patterns in data, predict issues before they happen and even create automated fixes before the issue occurs.
-
Do I need to be an AI expert to use AIOps tools?
Not by any means. Most AIOps platforms are built around user-friendly dashboards, low-code interfaces, and out-of-the-box integrations. While it is nice to have some basic data literacy, you do not need to be a data scientist—an ITOps team member (not a PhD in AI) should be able to leverage AIOps tools.
-
Is AI Ops suitable for small and medium-sized enterprises (SMEs)?
Absolutely! Most people relate AI Ops to large enterprises, but small and medium-sized enterprises can benefit too. Most AI Ops solutions have scalable features and pricing models so that the needs and budget of smaller organisations can use AIOps and enhance their IT operations.
-
What kind of data does AIOps use?
AIOps can pull from many sources of data- logs, metrics, traces, events, alerts, and even configuration data. AIOps ingests structured and unstructured data from all parts of your IT stack to form a single real-time view of system health. AIOps will use that data to find anomalies, correlate events, and drive automation.
-
How does AI Ops support cloud and hybrid environments?
AI Ops gives visibility and control across cloud, on-prem, and hybrid infrastructures. It supports monitoring resource usage and compliance, and delivering performance optimization by analyzing data across all environments and providing unified management.

