
Key Concept Extraction: Intelligent Audio Transcript Analytics Extracting Key Phrases for Scaling Industrial NLP Applications
The COVID?19 pandemic that hit us last year brought a massive cultural shift, causing millions of people across the world to switch to remote work environments overnight and use various collaboration tools and business applications to overcome communication barriers. However, this generates humongous amounts of data in audio format. Converting this data to text format provides a massive opportunity for businesses to distill meaningful insights. One of the essential steps for an in-depth analysis of voice data is ‘Key Concept Extraction,’ which determines the business calls’ main topics. Once the identification is accurately completed, it leads to many downstream applications. One way to extract key concepts is to use Topic Modelling, which is an unsupervised machine learning technique that clusters words into topics by detecting patterns and recurring words. However, it cannot guarantee precise results and may present many transcription errors when converting audio to text. Let’s glance at the existing toolkits that can be used for topic modelling.
Some Selected Topic Modelling (TM) Toolkits
- Stanford TMT : It is designed to help social scientists or researchers analyze massive datasets with a significant textual component and monitor word usage.
- VISTopic : It is a hierarchical visual analytics system for analyzing extensive text collections using hierarchical latent tree models.
- MALLET : It is a Java-based package that includes sophisticated tools for document classification, NLP, TM, information extraction, and clustering for analyzing large amounts of unlabelled text.
- FiveFilters : It is a free software solution that builds a list of the most relevant terms from any given text in JSON format.
- Gensim : It is an open-source TM toolkit implemented in Python that leverages unstructured digital texts, data streams, and incremental algorithms to extract semantic topics from documents automatically.

Tredence’s AI Center of Excellence (AI CoE)
Our AI CoE team has developed a custom solution for key concept extraction that addresses the challenges we discussed above. The whole pipeline can be broken down into four stages, which follow the “high recall to high precision” system design using a combination of rules and state-of-the-art language models like BERT.
Pipeline:
1) Phrase extraction : The pipeline starts with basic text pre-processing, eliminating redundancies, lowercasing texts, and so on. Next, use specific rules to extract meaningful phrases from the texts.
2) Noise removal: This stage of the pipeline uses the above-extracted phrases to remove noisy phrases based on signals mentioned below:
- Named Entity Recognition (NER): Certain NER such as quantity, time, and location type that are most likely to be noise for the given task are dropped from the set of phrases.
- Stop-words: Dynamically generated list of stop words and phrases obtained from casual talk removal [refer to the first blog of the series for details regarding casual talk removal (CTR) module] are used to identify noisy phrases.
- IDF: IDF values of phrases are used to remove common recurring phrases, which are part of the usual greetings in an audio call.
3) Phrase normalization: After removing the noise, the pipeline proceeds to combine semantically and syntactically similar phrases. To learn phrase embedding, the module uses state-of-the-art BERT language model and domain trained word embeddings. For example, “Price Efficiency Across Enterprise” and “Business-Venture Cost Optimization” will be clubbed together by this pipeline as they essentially mean the same.
4) Phrase ranking: This is the last and final stage of the pipeline, which ranks the final set of phrases using various metadata such as frequency, number of similar phrases, and linguistic POS patterns. These metadata signals are not comprehensive, and other signals may be added based on any additional data present. To illustrate the above pipeline, we have provided few set of bigrams and output of each module.
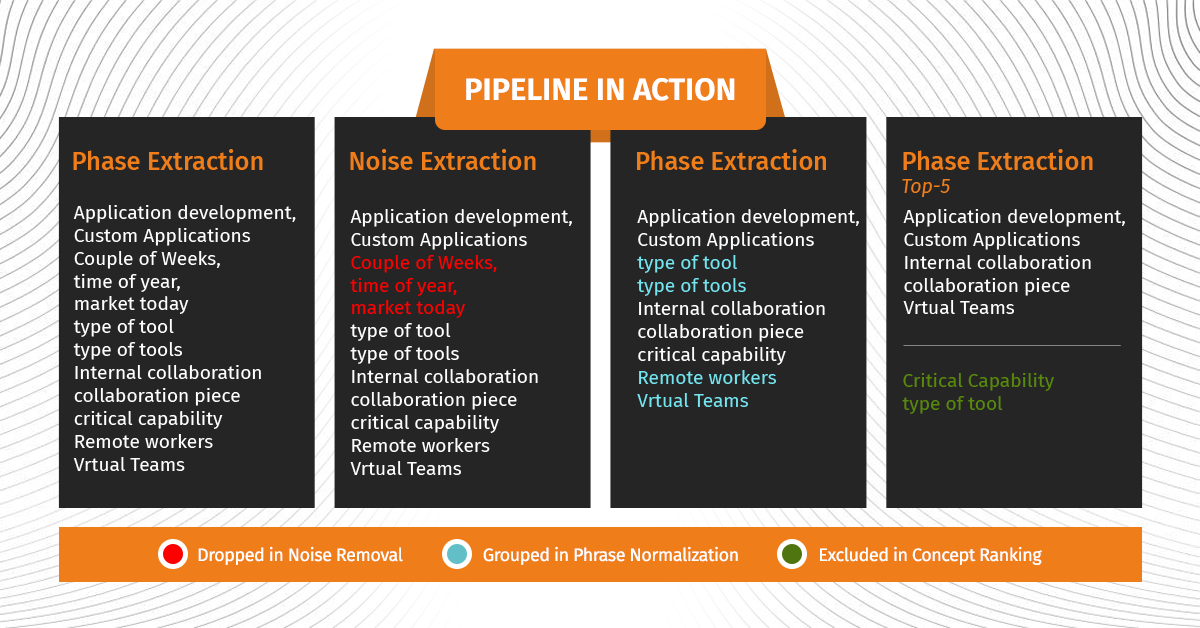
The above-mentioned stages of the pipeline provide broad functionalities of each sub module and are flexible enough to incorporate any changes depending upon the domain and use case, i.e., could be applied for problems like customer feedback text analysis or any other textual data.
Pipeline in action
Tredence has recently partnered with Fortune 100 Research and Advisory client to extract key topics discussed in their client inquiry calls. The accuracy provided by the above-discussed pipeline provided results at par with domain experts. The key highlight of using the above approach is that it’s highly customizable and doesn’t need any training data to match the near-human performance.

AUTHOR - FOLLOW
Siddharth Shukla
Data Scientist
Topic Tags

![AI Bias: How It Impacts AI Systems [+Best Practices to Prevent It]](/uploads/img/blog-img-1748942824.png)




Trackbacks/Pingbacks