
 LinkedIn
LinkedIn

On June 18, 2020, Databricks announced the support of Apache Spark 3.0.0 release as part of the new Databricks Runtime 7.0. Interestingly, this year marks Apache Spark’s 10th anniversary as an open-source project. The continued adoption for data processing and ML makes Spark an essential component of any mature data and analytics platform. Spark 3.0.0 release includes 3,400+ patches, designed to bring major improvements in Python and SQL capabilities. Many of our clients are not only keen on utilizing the performance improvements in the latest version of Spark, but also expanding Spark usage for data exploration, discovery, mining, and data processing by different data users.
Key improvements in Spark 3.0.0 that we evaluated:
-
-
Spark-SQL & Spark Core:
- Adaptive Query Optimization
- Dynamic Partition Pruning
- Join Hints
- ANSI SQL Standard Compliance Experimental Mode
-
-
-
Python:
- Performance improvements for Pandas & Koalas
- Python type hints
- Addition to Pandas UDF
- Bettered Python error handling
-
-
-
New UI for Structured Streaming:
-
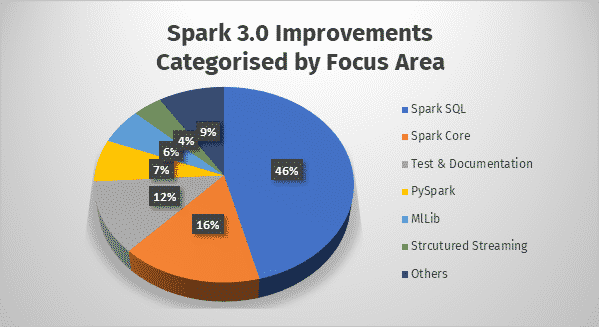 Figure 1: Area-wise breakdown of Spark improvements focused in Release 3.0.0
Figure 1: Area-wise breakdown of Spark improvements focused in Release 3.0.0
As represented from Figure 1, the enhancements of Apache Spark 3.0.0 are included in the two most popular Spark languages – SQL and Python.
SQL Engine Improvements:
As a developer, I wish the Spark engine was more efficient with:
- Optimizing the shuffle partitions on its own
- Choosing the best join strategy
- Optimizing the skew in joins
As a data architect, I spend considerable time optimizing the issues above as it involves conducting tests on different data volumes and settling on the most optimal solution. Developers have options to optimize by:
- Reducing shuffle through coalesce or better data distribution
- Better memory management by specifying the optimum number of executors
- Improving garbage collection
- Opting to use join hints to influence the optimizer when the compiler is unable to make a better choice
But, it’s always a daunting task to choose the correct shuffle partitions on varying production data volumes, handle the join performance bottlenecks induced by data skewness, or choosing the right dataset to be broadcasted before the join. Even after many tests, one can’t be sure about the performance as data volumes change over time, and data processing jobs take time, which results in missing the SLAs in Production. Even with optimal design and build combined with multiple test cycles, performance problems may come up in Production workloads, which significantly reduces the overall confidence among IT and the business community.
Spark 3.0.0 has the solutions to many of these issues, courtesy of the Adaptive Query Execution (AQE), dynamic partition pruning, and extending join hint framework. Over the years, Databricks has discovered that over 90% of Spark API calls use DataFrame, Dataset, and SQL APIs along with other libraries optimized by the SQL optimizer. It means that even Python and Scala developers route most of their work through the Spark SQL engine. Hence, it was imperative to improve the SQL Engine and, thus, the 46% focus, as seen in the figure above.
We did a benchmark on a 500GB dataset with AQE, and dynamic partition pruning enabled on 5+1 node Spark cluster with 168GB RAM total. It resulted in a 20% performance improvement of a ‘Filter-Join-GroupBy using four datasets’ and a 50% performance improvement on ‘Cross Join-GroupBy-OrderBy using three datasets.’ On average, we saw an improvement of 1.2x – 1.5x with AQE enabled. A summary of the TPC-DS benchmark for the 3TB dataset can be found here:
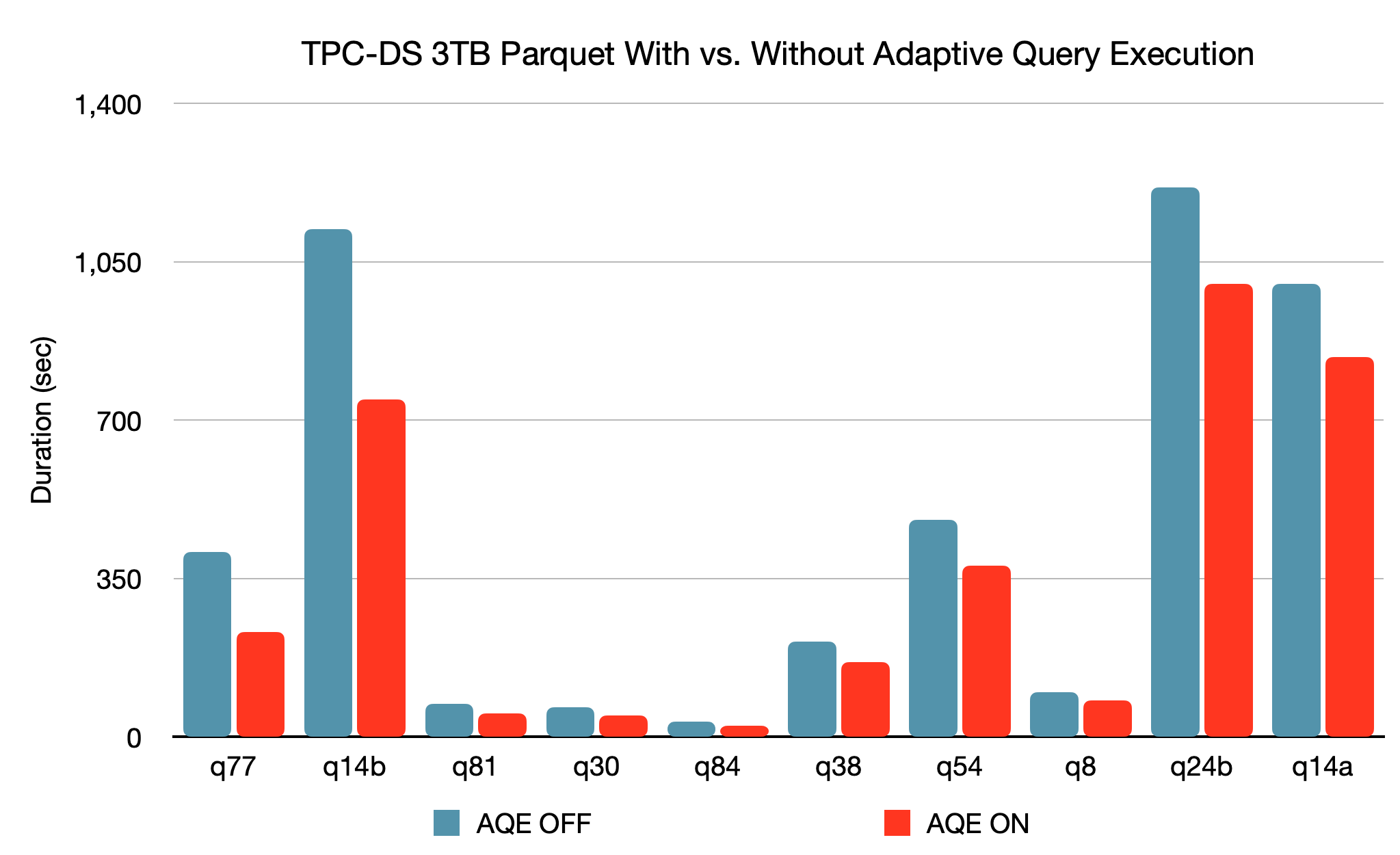
Source: Click here
Advanced Query Engine
This framework dramatically improves performance and simplifies query tuning by generating a better execution plan at runtime, even if the initial plan is suboptimal due to the loss/inaccuracy of data statistics. Three major contributors to this are:
- dynamic coalescing shuffle partitions
- dynamically switching join strategies
- dynamically optimizing skew joins
Dynamic Partition Pruning
Pruning helps the optimizer avoid reading the files (in partitions) that cannot contain the data your transformation is looking for. This optimization framework automatically comes into action when the optimizer cannot identify the partitions that could have skipped at compile time. This works at both the logical and physical plan levels.
Python Related Improvements
After SQL, Python is the most commonly used language in Databricks notebooks, and hence it is the focus of Spark 3.0 too. Many Python developers rely on Pandas API for data analysis, but the pain point of Pandas is that it is limited to single-node processing. Spark has been focusing on the Koalas framework, which is an implementation of Pandas API on Spark that can gel well with big data in distributed environments. At present, Koalas covers 80% of the Pandas API. While Koalas is gaining traction, PySpark has also been a hot choice amongst the Python community developers.
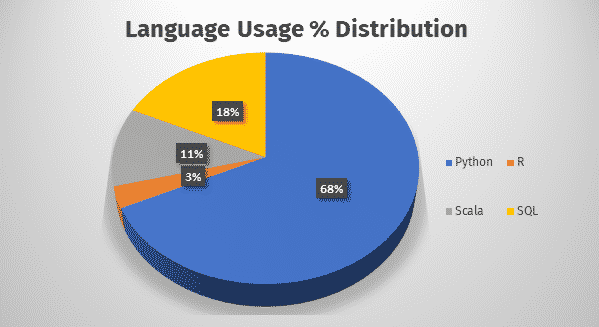 Figure 2: Language use in Databricks notebook.
Figure 2: Language use in Databricks notebook.
Spark 3.0 brings several performance improvements in PySpark, namely –
- Pandas APIs with type hints – Introduction of new Python UDF Interface, which takes the help of Python type hints to increase the UDF usage among developers. These are executed by Apache Arrow to facilitate the data exchange between the JVM and Python driver/executor with near-zero (de)serialization cost
- Addition to Pandas UDFs and functions API – The release brings two major additions: Iterator UDFs and Map functions, which will help with data prefetching and expensive initialization
- Error Handling – This was always the developer town’s talk because of the poor and unfriendly exceptions and stack trace. Spark has taken a major leap to simplify the PySpark exceptions, hide unnecessary stack trace, and make them more Pythonic.
Below are some notable changes being introduced as part of Spark3.0 –
- Java 8 prior to version 8u92 support, Python 2 and Python 3 prior to version 3.6 support, and R prior to version 3.4 support is deprecated as of Spark 3.0.0.
- Deprecating MLLib – based on RDD, not data frames.
- Deep learning capability – Allows Spark to take advantage of GPU hardware if it is available. It also allows TensorFlow on top of Spark to take advantage of GPU hardware.
- Better Kubernetes integration – introduces new shuffle service for Spark on Kubernetes that will allow dynamic scale up and down.
- Support for binary files – loads the whole binary file into a binary file of a data frame, useful for image processing.
- For graph processing, SparkGraph(Morpheus), not GraphX, is the way of the future.
- Support for delta lake out of the box and can be used just as it is used, for example, with parquet.
All in all, Databricks fully adopting Spark 3.0.0 helps developers, data analysts, and data scientists through the significant enhancements to SQL and Python. The introduction of Structured Streaming Web UI will help track the aggregated metrics and detailed statistics about the streaming jobs. Significant Spark-SQL performance improvements and ANSI SQL capabilities accelerate the time to insights and improve adoption among the advanced analytics users in any enterprise.

